🚀 Check out this trending post from Hacker News 📖
📂 Category:
📌 Key idea:
Hey all. TinyKVM was open-sourced this february and since then I’ve been working on some things that are very much outside of the scope of the original implementation. Originally, it was intended to be for pure computation (and that is very much still possible, and is the default), but makes it hard to use TinyKVM outside of specialized use-cases. So, I’ve relented and implemented limited support for running unmodified executables in TinyKVM. Specifically, run-times like Deno, Python WSGI and similar run-times like Lune.
I would like to make a special shout-out to Laurence Rowe who championed KVM server, which has now become almost a de-facto CLI for TinyKVM servers. It’s very much work in progress, but give it a try if you’re interested in these kinds of things.
In order to achieve this I picked the very untraditional route of implementing system call emulation, but as poorly as possible. And as few system calls as possible. I think today there is 50 real system calls (gVisor has ~200 for comparison), and all of them will to some degree make shit up (for lack of a better term). The goal is to avoid accessing the (shared) Linux kernel when at all possible, but give sanitized access when permitted and appropriate. To give an example of what I mean by this: The only allowed ioctl operations are setting and getting non-blocking mode (FIONBIO), and reading the number of available bytes (FIONREAD). This minimalist system call API is currently able to run quite a few complex run-times unmodified. Programs are surprisingly good at handling failing system calls, or suspicious return values. If you put a jailer on top it should be good enough for production, but I do still recommend to use TinyKVM in pure compute mode. Something like Jailer + TinyKVM + Deno + per request isolation.
Per-Request Isolation
Per-request isolation is apparently not that common. I could not find any other production-level support other than in wasmtime (and previously Lucet). But, due to its lack of in-guest JIT support it will not be able to compete with Deno so I will just focus on the positives: It uses a clever lazy MADV_DONTNEED mechanism which delays the cost. You can go test wasmtime’s per-request isolation right now with the hello-wasi-http example.
In TinyKVM there are two reset modes, which together forms hybrid per-request isolation that is capable of maintaining a low memory footprint. Together, it makes the fastest per-request isolation that exists right now. It’s main mode will directly rewrite all touched pages in a VM fork back to their original contents and then leave pagetables (and TLBs) intact. This mode has turned out to be the fastest, but as it leaves the memory footprint untouched it can only grow memory usage for forked VMs. Forked VMs are tiny to begin with, but for large page rendering work it may be a concern, hence there’s a second mode triggered by a fork using memory above a limit. The second mode resets the entire VM with pagetables and everything, which happens when it uses working memory above a certain limit or an exception occurs during request handling. It’s not particularly expensive on its own, but if every VM fork would do it all the time the IPIs and coherency chatter would be a bottleneck.

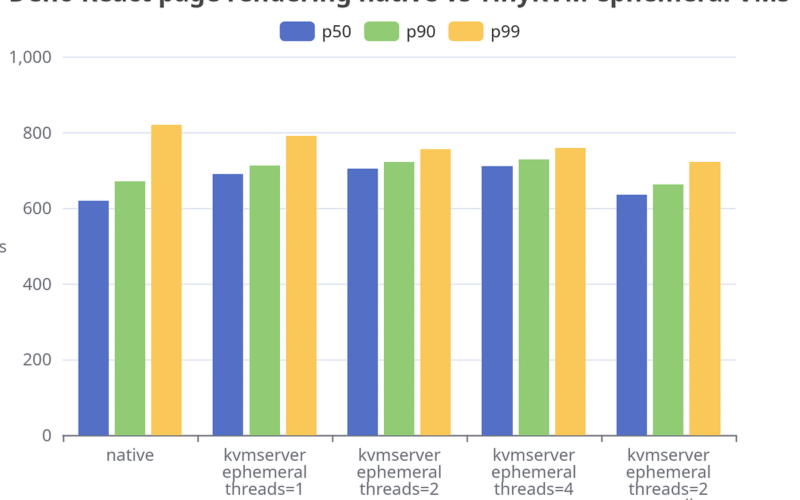
So we ran a full Deno page rendering benchmark in TinyKVM and then also the very same (unmodified) benchmark natively. We made GC single-threaded in order to compare equally. It would normally run async in another thread, but you’d still have to pay the cost of doing it. What we found was that TinyKVM generally had lower p90+ latency, while native had better p50.
Now this is incredible. Per-request isolation is very very expensive. We are resetting an entire KVM VM every request back to its original state. And we’re doing it very close to native not doing it at all. We’re doing it with unmodified Deno, a big run-time, and with a full page rendering benchmark, a large piece of compute work that builds real memory pressure.
A new type of remote procedure call
One of the things not on my 2025 bingo card was creating a custom RPC mechanism. And, it’s not that great outside of its specific use-case.
I figured that if you loaded two binaries into the same address space, couldn’t you just call a function in the other just fine? Turns out yes, especially if you trap on the far jump (not a real far jump) and then switch a few important registers like the thread-pointer (FSBASE). So, if you have to ABI- or FFI-compatible programs you can essentially freely call functions in the other. Now, this sounds dangerous for sandboxing and kinda useless if you can just use a super-fast IPC like iceoryx2, but.. it turns out that super-fast IPC requires the other end to be always scheduled and crucially also requires that caller to not be adversarial and trample shared memory while you’re reading it. If both of those things are true, then go ahead and use fast IPC. Being able to directly call a remote party without depending on the scheduler it turns out is really really performant. A simple schbench benchmark will tell you all you need to know about what happens when the scheduler is busy. You can go do it on your own machine. It’s commonly a 2-digit number of milliseconds you can expect for p99. So, this new method is in fact the new king of this specific type of RPC. The only remaining part then is how do you deal with sandbox integrity? Turns out you can just not have the remote part mapped in at all, and then either:
- Directly resume the remote VM with your caller VMs address space already mapped in. This means that the remote VM is “higher privileged”, sort of. And you need a dedicated VM for persistence per caller. This is fine with tiny VM forks.
- Map in the remote VM just-in-time on the execution page fault, execute the remote function call, unmap it (and flush TLBs) on return (or any exception, timeout). This also means the remote VM is “higher privileged”.
So, what is this then? Are these two programs the same tenant? What does this have to do with per-request isolation?
Per-request isolation doesn’t have persistence. The entire request VM gets wiped on every request. It would be great if we could maintain something under certain conditions. So, then either it would have to make an expensive call out to a remote service (ala Binder on Android). Or, we could solve two problems in one: Allow tenants to have a program that is persistent, and give them direct scheduler-free access to it. That is, the persistent program would inform the system which functions are callable, so you can’t just randomly jump to remote memory, but you can jump to any registered address directly, which immediately executes the remote function call. Example:
static void my_backend(const char*, const char*)
🔥
Here’s a simple C++ request handler. Instead of jumping directly to a remote VM function, we choose to directly resume the remote VM, as it is running a complex run-time. Deno in fact.
while (true) What do you think?
What’s omitted is encoding the answer back into the buffer zero-terminated. But maybe you got the gist of it: The buffer is zero-copy and we write directly into it. The only remaining thing to do after writing to the buffer is to go back to waiting.
While everything is zero-copy, you will have to duplicate anything that you want to persist. You can use allocators to allocate for the caller.
This feature currently executes safely on the order of 2 microseconds wherever I’ve benchmarked it. It’s cost is partly having to context switch twice per call, and partly having to flush TLBs. It can be improved with INVPCID and only flushing the remote side, but I haven’t done that yet.
Concurrent access to the remote is possible with an idea I’ve had in my head for a while: Create N threads in the remote VM and register them for use by callers. I think this is essentially how most people would expect/hope it would work. You’d have to lock and synchronize things normally. However, for now I am currently using serialized access to the remote VM. It’s also possible to fork it into many copies to avoid serializing access but that only helps you in certain cases like connection pooling to a database. That is of course supported already. If you want a single-source-of-truth then you probably also want to serialize access to the remote.
During remote calls the caller VM has to be paused. There’s no way around it, otherwise it can trample memory used by the remote VM and crash it. While zero-copy IPC exists where both can run at the same time, it’s fundamentally a question of trust and integrity. You simply can’t do that with two separate sandboxes talking to each other.
Anyway. I hope that was an introduction to the concept, at least. It’s not your everyday feature. It likely won’t solve your problems. I just think it’s a really cool idea. And I do use it, of course. For limited persistence with per-request isolation.
VM snapshots
The last topic of this post is VM snapshots. A feature that many have asked about for TinyKVM. Wouldn’t it be nice if you could snapshot a VM, transport it somewhere else, and resume it? Well, now you can. The feature is implemented by backing all of physical memory with a single file, and then adding some VM state on top and a user-provided section at the very end. This combines all state into a single file with holes.
For reference, a Deno JS hello world instance is 192MiB RSS after initializing the first time. If you save that state into a snapshot and resume it, the file is 135MiB on disk (2.4GiB logical), and RSS is 50MiB after starting with 32 VM forks.
$ du -h program/deno/deno.mem
135M program/deno/deno.mem
The startup time is 0.7ms with everything in page cache. Clearing the page cache is not a simple matter as you have to clear any caching on the disk as well. This typically means you’ll need a custom device. I don’t have all the answers right now, but I suspect it will be around 20ms to load the program from disk with everything cold. My guess is nothing other than that’s the worst number I’ve gotten so far.
We’re currently working on recording the actually accessed pages of a request and only preloading those. Combined with a full clear of all relevant caches we hope to see that it loads faster than any other alternatives in this space. Fast cold start is of course a crowded space, but you never know what you will find until you try. Because we will be able to know more or less the exact pages that are going to be used by the next request, we might be able to populate just the right pages and avoid loading pages that aren’t going to be used. Typically Linux will load ranges of pages optimistically based on faults. Avoiding that can save some time. We are also hosting just a single process. It’s just Deno, and nothing else. Of course, requests differ, but they should have many things in common.
I think I will end this post here. This is as far as I’ve gotten. Thanks for reading!
-gonzo
⚡ Tell us your thoughts in comments!
#️⃣ #update #TinyKVM #Hey #TinyKVM #opensourced #fwsGonzo #Oct
🕒 Posted on 1761456516