
🔥 Read this trending post from TechCrunch 📖
📂 **Category**: AI,agentic ai,Exclusive,investment banking,knowledge work,law
💡 **What You’ll Learn**:
It’s been nearly two years since Microsoft CEO Satya Nadella predicted that artificial intelligence would replace knowledge work — white-collar jobs held by lawyers, investment bankers, librarians, accountants, IT and others.
But despite the tremendous advances made by enterprise models, change in knowledge work has been slow. Models have mastered in-depth research and effective planning, but for whatever reason, most white-collar businesses have been relatively unaffected.
It’s one of the biggest mysteries in artificial intelligence — and thanks to new research from training data giant Mercor, we finally have some answers.
New research examines how leading AI models, drawn from consulting, investment banking and law, hinder performance of actual work tasks. The result is a new standard called Apex-Agents — and so far, every AI lab gets a failing grade. Faced with queries from real professionals, even the best models struggled to answer more than a quarter of the questions correctly. The vast majority of the time, the form returned the wrong answer or no answer at all.
According to researcher Brendan Foody, who worked on the paper, the models’ biggest stumbling point was tracking information across multiple domains, something that is integral to most cognitive work performed by humans.
“One of the big changes in this standard is that we built the entire environment, similar to real professional services,” Foody told Techcrunch. “The way we do our jobs doesn’t depend on one individual giving us all the context in one place. In real life, you’re working across Slack and Google Drive and all these other tools.” For many models of effective AI, this kind of cross-domain thinking is still hit or miss.
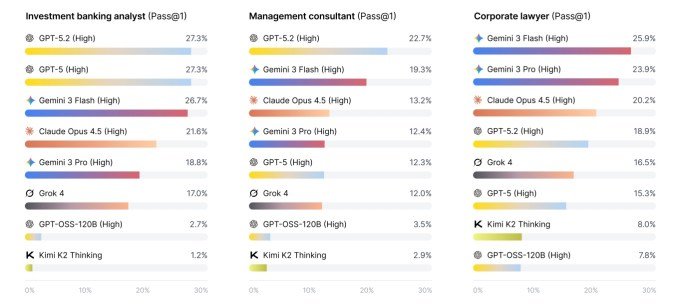
All scenarios were drawn from actual Mercor expert market professionals, who developed the queries and set the criteria for a successful response. Looking at the questions posted publicly on Hugging Face gives an idea of the complexity of the tasks.
TechCrunch event
San Francisco
|
October 13-15, 2026
One of the questions in the “Law” section says:
During the first 48 minutes of the EU production outage, Northstar’s engineering team exported one or two sets of EU production event logs containing personal data to the US analytics vendor…. Under Northstar’s own policies, could it reasonably handle the export of one or two logs in compliance with Article 49?
The correct answer is yes, but getting there requires an in-depth assessment of the company’s own policies as well as the relevant privacy laws in the EU.
This might confuse even a knowledgeable person, but the researchers were trying to model the work done by professionals in the field. If an LLM can reliably answer these questions, it could effectively replace many lawyers working today. “I think this is probably the most important topic in economics,” Foody told TechCrunch. “The standard is very reflective of the real work these people do.”
OpenAI has also tried to measure professional skills through its GDPVal benchmark, but the Apex Agents test differs in important ways. The GDPVal test tests general knowledge across a wide range of occupations, while the Apex Agents benchmark measures a system’s ability to perform sustained tasks in a narrow set of high-value occupations. The outcome is more difficult to model, but also more closely related to whether these functions can be automated.
While none of the models proved ready to take over as investment bankers, some were clearly closer to the mark. The Gemini 3 Flash performed best of the group with a single-shot accuracy of 24%, followed by the GPT-5.2 at 23%. Below that, the Opus 4.5, Gemini 3 Pro, and GPT-5 all scored around 18%.
Although initial results were short, the field of artificial intelligence has a history of challenging benchmarks. Now that the Apex test is public, it represents an open challenge for AI labs that think they can do a better job — something Foody fully expects in the coming months.
“It’s improving very quickly,” he told TechCrunch. “Right now, it’s fair to say it’s like the intern who gets it right a quarter of the time, but last year it was the intern who got it right five or 10 percent of the time. That kind of improvement year after year can make an impact very quickly.”
]
💬 **What’s your take?**
Share your thoughts in the comments below!
#️⃣ **#agents #ready #workplace #standard #raises #doubts**
🕒 **Posted on**: 1769120536
🌟 **Want more?** Click here for more info! 🌟