🚀 Read this must-read post from Hacker News 📖
📂 **Category**:
✅ **What You’ll Learn**:
Ever since it showed up on my GH feed, Karpathy’s Autoresearch was rattling around in the back of my mind. I wanted to try it on a research problem I fully understood. So this weekend, I picked up my old research code from eCLIP , dusted it off the legacy dependencies and gave it to Claude Code. And just let it cook while I did some chores around the house.
This is my journey…
Core Idea
Autoresearch is a simple constrained optimization loop with an LLM agent in the middle. The agent iteratively improves some eval metric by modifying a single file (train.py), while reading instructions from program.md. I added a scratchpad.md file for the agent to use as working memory to document its thought process and experiment history.
In the program.md, I split the exploration into “phases”, starting with some obvious hyperparameter tuning, then moving on to small architectural changes and finally some moonshot ideas. In the final phase, I basically let the agent run with minimal constraints, and gave it web access to read papers and look for new ideas.
The whole thing is a tight loop: hypothesize → edit → train → evaluate → commit or revert → repeat.
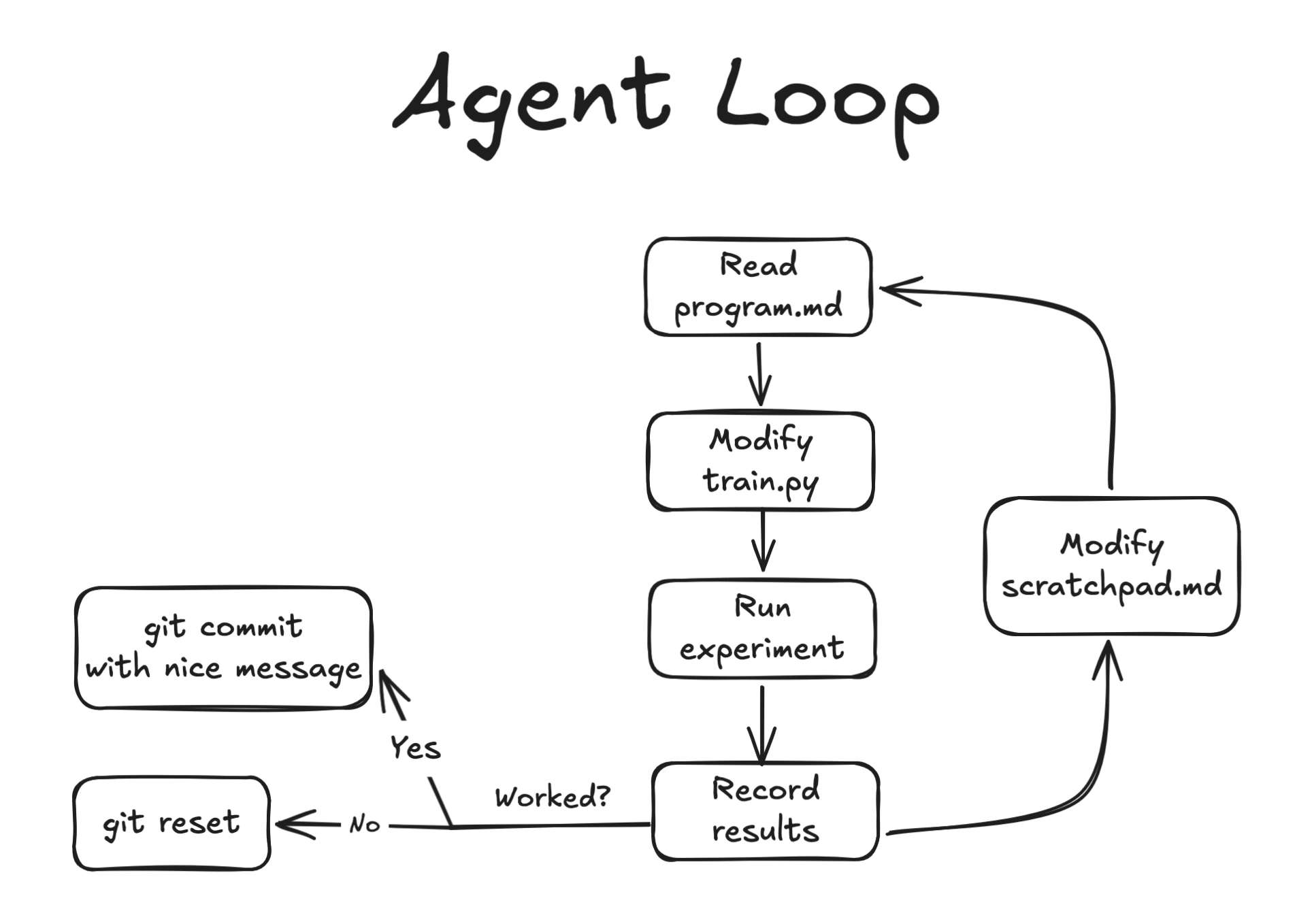
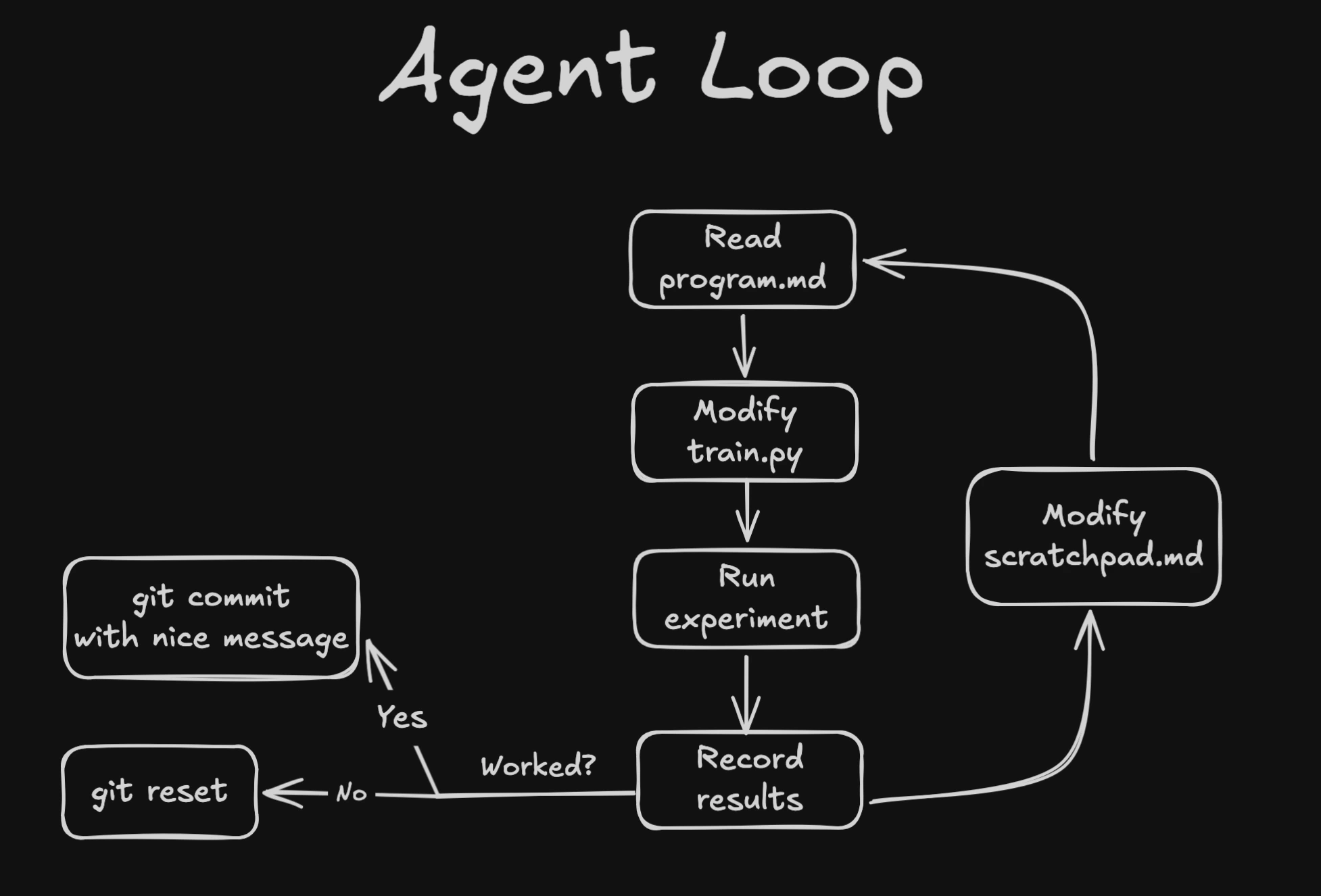
The experiment should be short, around 5 minutes wall clock per run, to encourage quick iterations and prevent overfitting to noise. The agent is free to change anything in train.py as long as it runs within the time budget.
Sandboxing
Since I was paranoid about letting the agent run arbitrary code in my workstation, I containerized the training loop and removed network access. The whole experimentation flow is orchestrated by a run.sh. Then I lock down Claude Code’s permissions to only edit these two files and run run.sh. No direct Python execution, no pip installs, no network access, no git push, etc.
I won’t bore you with the details, you can check out the repo here!
Dataset
The original paper used several medical X-ray datasets which I don’t have access to anymore, so I needed a new dataset with spatial annotations to test the expert attention mechanism. I picked the Ukiyo-eVG dataset: ~11K Japanese woodblock prints with phrase → bounding box annotations from the CIGAr paper (ECCV 2024 VISART).
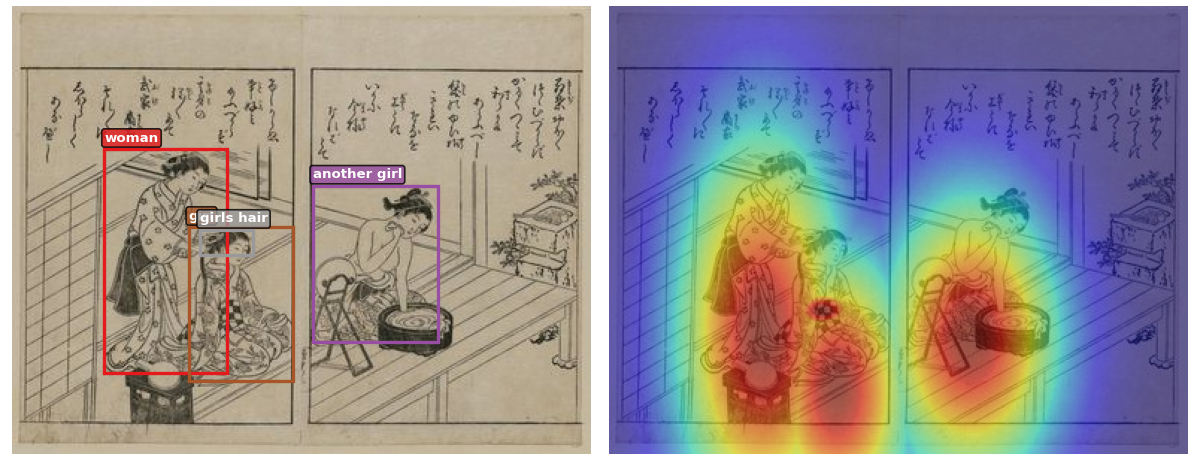
Heatmaps obtained from bounding boxes guide the model to focus on specific regions.
The bounding boxes were converted to gaussian heatmaps and fed into the model as an additional input, similar to how radiologist eye-gaze heatmaps work in the original eCLIP paper.
Hello — Claude Code
I had a busy week and a lot of chores piling up, so I just pointed Claude at my old research code and went to do laundry. It upgraded the python env of my old research codebase, wrote the ingestion code for the new dataset, and wrote the scaffolding for the experiment loop.
I set up the CV splits, evaluation logic and some initial ideas for the program.md.
For the eval metric we picked Mean Rank of the retrieved embeddings. I didn’t put much thought into it — in hindsight, Median Rank would’ve been a better choice since it’s more robust to outliers. But we just needed something intuitive that clearly tells the agent whether a change is good or bad. Since Recall@K is the standard for reporting final results anyway, Mean Rank just needed to point in the right direction.
Other details
- CLIP backbone : ViT-Small (22M) + DistilBERT (66M) + HeatmapProcessor · ~90M params
- Training: 800 steps (~3 min per run on a RTX 4090)
- Eval: Mean Rank on a held-out test set of 1K images, with Recall@K as a sanity check.
- Baseline: Val mean rank of 344.68, with imgtxt R@1 of 17.2% and txtimg R@1 of 16.5%.
So how did it do?
I kicked off the loop on Saturday morning and let it run through the day, occasionally checking in to nudge the agent in the right direction. By the time I was done with groceries, the agent had already burned through a couple of dozen experiments and knocked off a huge chunk of the eval mean rank.
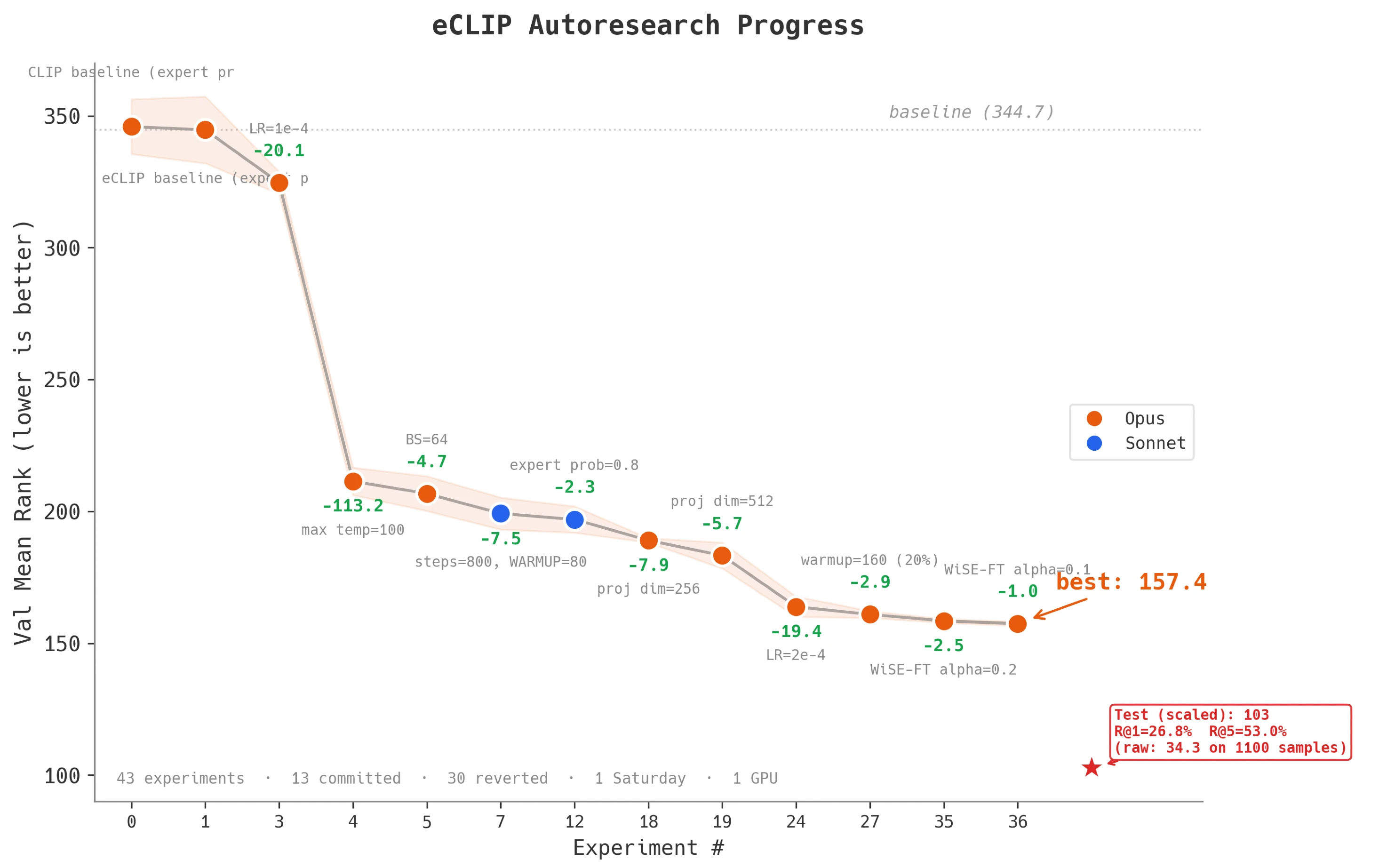
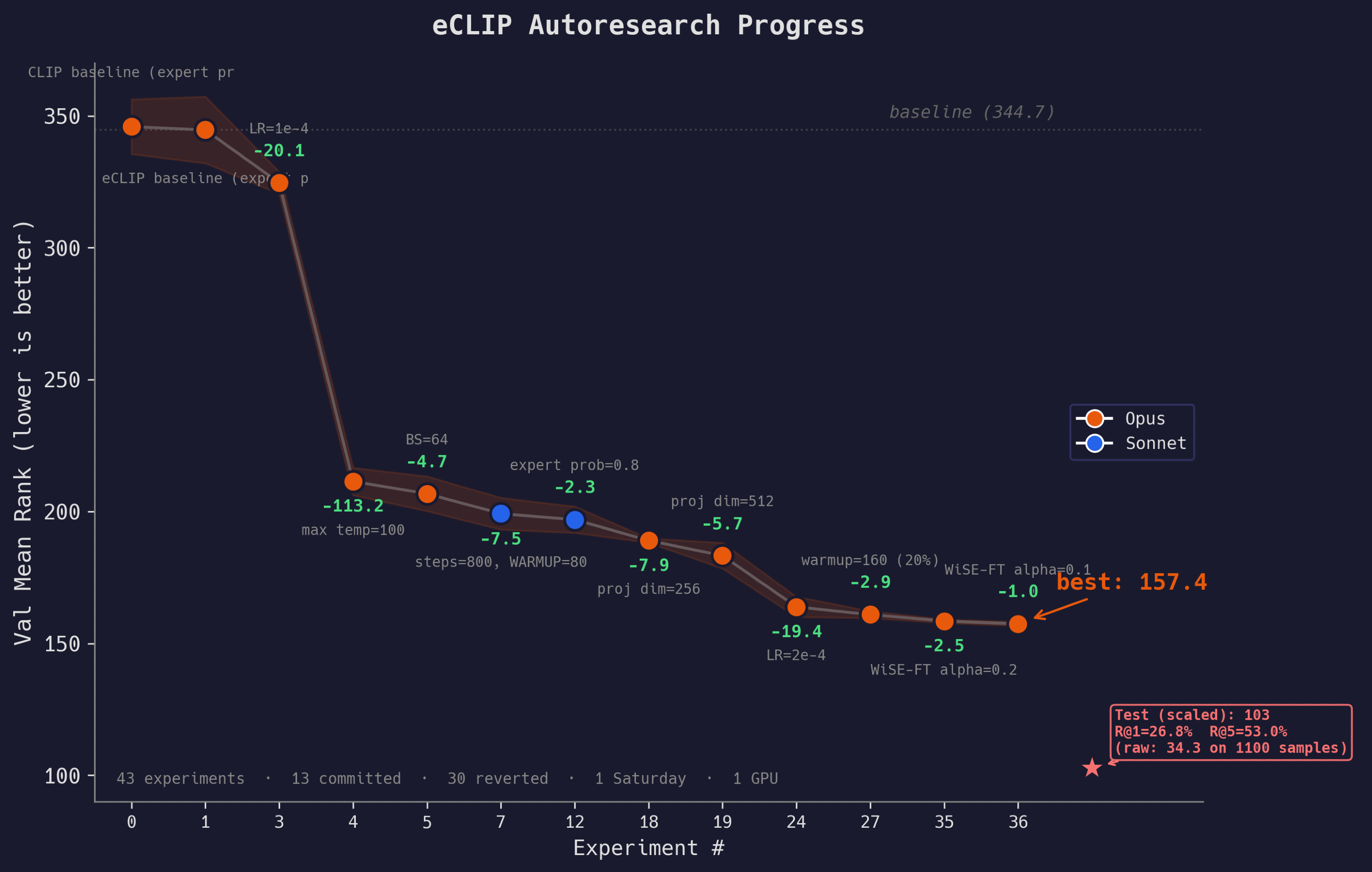
42 experiments · 13 committed · 29 reverted · 1 Saturday · 1 4090 GPU
By the end of the day, the agent ran 42 experiments, committing 13 and reverting 29. The mean rank dropped from 344.68 to 157.43 (54% reduction).
After the agent finished its exploration, I did one final training run on the full dataset. The test scores actually came out better than the validation scores. This meant we were underfitting during the short 800-step experiment runs, leaving performance on the table.
| Mean Rank | img→txt R@5 | txt→img R@5 | |
|---|---|---|---|
| Test | 34.30 | 53.0% | 51.4% |
So AGI?
Well…
-
Temperature clamp fix (−113 mean rank): It immediately went for a bug in my code. I had clamped the learnable temperature param at 2. It relaxed the limit, and boom, the eval dropped by 113 points. This was the single biggest win, worth more than all the architecture changes combined.
-
Optuna++ (-30 mean rank): Further gains came mostly from hyperparameter tuning. The agent acted like a hyperparameter optimization algorithm with some basic reasoning baked in. Increasing projection dimension and re-tuning the LR knocked off another 30 points. This is still tedious work that a human would do (and get minimal pleasure from), but the agent did it faster and more methodically.
-
Diminishing Returns: By the time we got to Phase 4 with the architectural changes, the success rate of the LLM’s hypotheses dropped significantly. The changes to the attention mechanism in the heatmap processor didn’t work out. Neither did the moonshot ideas in Phase 5. The agent was just throwing spaghetti at the wall, and most of it did not stick.
-
Sandbox is important: Towards the end, Claude Code sometimes forgot its permissions and started making weird bash calls, then complained and stopped looping. At one point it got tired of waiting for training to finish and just ended the conversation. I wouldn’t give it full autonomy just yet 🙂
Closing thoughts
Like with any LLM project, the first 90% of the work was super smooth and barely needed my intervention. The last 10% was a slog. This was a fun experiment that showed how an LLM agent can drive ML research in a structured way. When the search space is clearly defined, the commit-or-revert loop proposed in Autoresearch is a surprisingly effective search strategy. But when the agent ventured into the “unknown unknowns”, the optimization loop just exploded.
It is possible that the “make only one change per experiment” constraint was too tight for the moonshot ideas. Maybe we could have injected a planning stage into the Agent loop so it could think ahead. Or maybe deployed some subagents.
Maybe. But it was already time for dinner, and we were planning to watch a movie after that, so this was where Claude and I parted ways… until Monday of course.
Acknowledgements
- Ukiyo-eVG — ~11K Japanese woodblock prints with phrase→bounding box annotations from the CIGAr paper (ECCV 2024 VISART).
- Autoresearch by Andrej Karpathy for the original idea.
💬 **What’s your take?**
Share your thoughts in the comments below!
#️⃣ **#Autoresearch #research #idea #Blog**
🕒 **Posted on**: 1774292982
🌟 **Want more?** Click here for more info! 🌟