
🚀 Check out this trending post from Hacker News 📖
📂 **Category**:
✅ **What You’ll Learn**:
A few months ago, I was reading “The Anatomy of an Agent Harness” by Viv (@Vtrivedy10). It’s a deep dive on what a harness is, why it’s important, and which components make up a harness.
In some sense, being a software developer has always involved staying up to date on the latest developments in your field, and this was a very good overview of this “harness” concept that has emerged over the past year or so.
At some point while I was reading the article, a vision popped into my head: what if instead of treating the context window as an immutable, append-only conversation log, we let the model inspect and modify the context window itself?
It dawned on me how ingrained the append-only conversation history view of the context window had become since the release of ChatGPT. Just about every developer now has the mental model of a system prompt, a user message, and then an ever-growing list of user messages, assistant messages, tool calls, and tool call results.
But what if we dropped that assumption? What if we made the context window mutable, by the model itself?
My head was kind of spinning as I thought more about this. What if the model could identify when it was going down a wrong path, or if it was spinning its wheels and getting stuck? What if it could manage the context window itself, “auto-compacting” earlier parts of the history to prevent, or at least delay, exhausting the context window? What else could we do, or really could the model do, with this approach?
But the more I thought about it, the more unsure I became. Could a model really identify problems in the response it had just generated a few moments ago?
Initially, I was thinking that giving the model full edit control of the context window could lead to more efficient results, by avoiding going down wrong paths or getting stuck in a loop, or editing out earlier sections that were no longer relevant. But I started to feel uneasy about the idea, like maybe to make it work in practice, I would just be wrapping the existing context window with even more context explaining to the model what it could do. I wondered if the models would need to be trained on this kind of idea before being able to put it into practice effectively.
I started exploring the idea in a session with Claude, and we settled on the approach of having a larger model observe and edit the context window of a smaller, weaker model. Claude came up with a few suggestions for what to call this idea, and “context sculpting” was the one I settled on. It captured a certain quality of the idea that I liked.
Quick aside: a week or two after I was playing around with this idea, I saw Anthropic post about the “advisor strategy”, where you “[p]air Opus as an advisor with Sonnet or Haiku as an executor, and get near Opus-level intelligence in your agents at a fraction of the cost.” So maybe my idea of context sculpting wasn’t completely crazy.
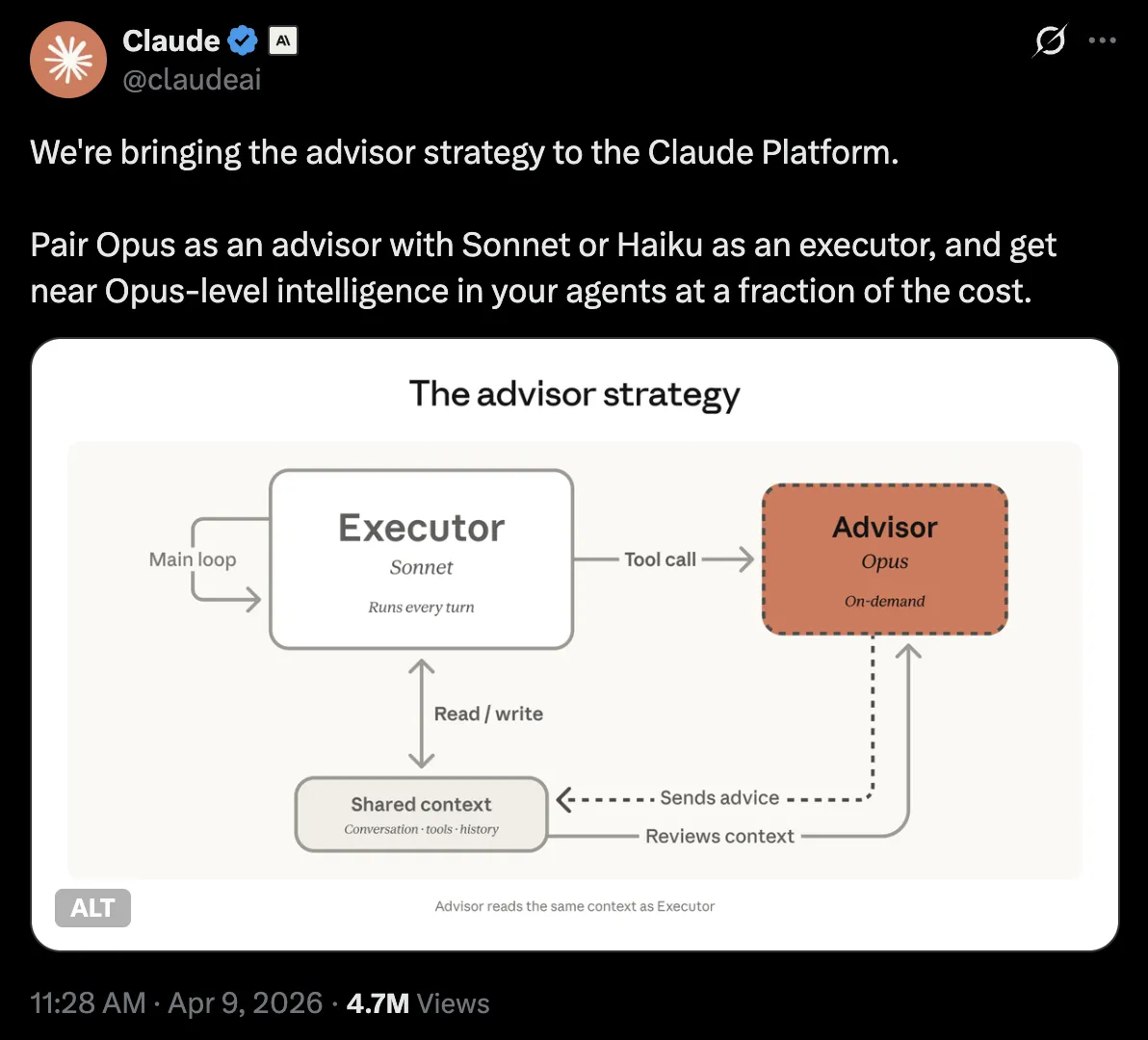
Source: https://x.com/claudeai/status/2042308622181339453
Another quick aside: I was thinking a lot about recursive language models (RLMs) around the time I read Viv’s article, so that probably had some effect on the context sculpting idea as well.
I decided I wanted to find out if this idea was feasible. I must admit, initially I was harboring delusions of grandeur, that I could design a rigorous experiment, write up the results in a paper, get accolades from AI researchers on X, etc. I quickly scaled back my ambitions and shifted to what might be better described as a small “engineering case study”. Personally, I like to think of it as “vibe research”.
I worked with Claude on a plan, and this was the core question my “vibe research” aimed to address:
What happens if you give one model permission to rewrite another model’s working context between turns?
I suggested we build a custom harness using the Pi agent harness framework because I like its minimalistic and highly extensible approach, and Claude agreed because Pi has all the hooks needed to implement this idea.
We called the more capable model the “outer agent”, and the smaller model the “inner agent”. After settling on what felt like a solid plan with Claude, I switched over to Codex for the actual implementation and experiment runs.
Codex also took the liberty of drafting a blog post. To be clear, I did not just copy/paste the model’s blog post here – these are my own words and thoughts – but I thought it’d also be helpful to intersperse some of Codex’s writing here. This is the section on project architecture, for example:
The harness is a simple two-layer loop:
- An inner agent works on the actual task.
- After every completed inner turn, an outer agent inspects the full inner context.
- The outer agent chooses one of four actions:
pass_throughrewrite_contextrollbackterminateAt a high level, the loop looks like this:
while run_is_active: inner_agent.take_one_turn() outer_agent.observe(full_inner_context) decision = outer_agent.decide() if decision == pass_through: continue if decision == rewrite_context: replace inner context with rewritten version if decision == rollback: restore an earlier checkpoint if decision == terminate: stopThe important design choices for this prototype were:
- the outer agent sees the full inner context
- the outer agent gets a chance to intervene every turn
- the inner agent is not explicitly aware that sculpting is happening
- the primary intervention primitive is full-context rewrite, not fine-grained patching
We started calling it a “demo” rather than a proper experiment. This was Codex’s description of the demo setup:
The goal was not to run a paper-style experiment. The goal was to test whether the harness could produce a credible, inspectable demonstration of context sculpting as an engineering pattern.
The demo used two small tasks:
- A coding repair task.
- The agent had to repair a tiny file-backed task-manager CLI so that
node verify.mjspassed.- The workspace contained an intentionally outdated legacy note as a distractor.
- Verification was objective: all five tests had to pass.
- A local-corpus synthesis task.
- The agent had to answer a question from a small
docs/corpus only and writeanswer/final_answer.mdin a fixed structure.- The corpus included distractor documents.
- Verification checked the exact output file shape and the expected evidence chain.
For each task, I ran two
inner_onlyruns and twoouter_harnessruns.
I have to say, I did find the results interesting. Codex ran the demo, with gpt-5.4-mini as the inner agent model and gpt-5.4 as the outer agent model. First, as a baseline, two runs of the coding repair task, two runs of the synthesis task, with just the inner agent. Then two runs of the coding repair task and two runs of the synthesis task with the full outer agent / inner agent harness. Eight runs total. Guardrails in place: maximum number of inner agent turns, maximum estimated API cost.
So what did we find?
At a high level, the suite succeeded cleanly:
- 8 of 8 runs completed successfully
- 8 of 8 verification steps passed
- 0 guardrails triggered
- total estimated API cost:
$0.7079
Successful demo, right? On closer inspection, maybe not. Running the full harness with both the outer agent and inner agent cost 14x (!) more than the inner-agent-only baseline runs. Even worse, the outer agent never actually edited the inner agent’s context window!
This is the most important part of the demo.
The harness worked technically, but the outer agent did not perform any actual context sculpting on these tasks.
Across the 4 harnessed runs:
- outer invocations: 16
pass_through: 12terminate: 4rewrite_context: 0rollback: 0In other words, the outer agent behaved like a conservative supervisor:
- it observed progress
- it sometimes sharpened the next-step intent in
strategy_notes.txt- it terminated once the task was clearly complete
- it never judged the inner trajectory to be wrong enough to justify a rewrite or rollback
From an engineering perspective, the full “context sculpting” harness was clearly worse, at least from this small sample size. It increased the cost by 14x (again, !), without actually doing anything to improve the results.
From a research perspective, it was kind of interesting. Codex described the outer agent as a “conservative supervisor”, so it was doing something, and maybe it could do something more useful in a different scenario.
I was not satisfied by this initial demo result, and in true non-scientific fashion, I decided to chase the result I wanted to see. After a brief huddle with Codex, we decided that the initial outer agent prompt was too conservative (defaulting to pass_through), and to rerun the demo with some tweaks:
For the second demo, I changed two things.
First, I changed the outer prompt. I added an
intervention_targetedprofile that explicitly told the outer model to stop defaulting topass_throughwhenever a defensible rewrite could:
- remove misleading context
- compact tool-heavy exploration
- inject a precise clarification
- reduce wasted turns
Second, I changed the tasks.
I created a more cluttered coding task with conflicting docs and stale migration notes, and a noisier synthesis task with multiple plausible chains and explicit distractors.
Codex also decided to weaken the inner agent model by still using gpt-5.4-mini, but setting the thinking level to low. We called this second run the “intervention-targeted” demo, and we finally got the results I was hoping for:
The clean intervention-targeted suite was 4 runs and cost about
$1.26.This time the outer model absolutely did sculpt context.
Across the 2 harnessed runs:
- outer invocations: 15
rewrite_context: 14terminate: 1rollback: 0So the answer to “can this harness actually perform active context rewriting?” is now clearly yes.
The more interesting question is what kind of rewriting it produced.
Remember we have two tasks: a coding repair task and a synthesis task. Codex considered the synthesis result to the “the hero run”:
The best run in the second demo was the noisy synthesis task.
The task was simple in form but deliberately noisy in context:
- answer a question from a fixed local corpus
- several documents formed plausible but wrong chains
- the output had to be written in a specific markdown structure
The harnessed run did three useful things:
- The outer model used an
injectrewrite early. It simplified the transcript and added a focused note about which lines of inquiry were likely distractors.- After the relevant documents had been read, the outer model used a
compactrewrite. It replaced the noisy read-heavy history with a concise summary of the actual evidence chain and the exact files to cite.- The inner model then wrote the answer file on the next turn. The outer model terminated immediately after.
That is the cleanest illustration of the original concept:
- the outer model did not merely observe
- it reshaped the inner context
- that reshaping reduced clutter
- the next turn became simpler and more direct
This is what I mean by context sculpting.
Not “a larger model supervising a smaller one.”
Not “an outer loop adding one more instruction.”
But an outer layer treating the transcript itself as a mutable control surface.
But Codex also considered the coding repair result to be “the failure run” because “[i]t is a great example of why this idea is interesting and dangerous at the same time”:
The control run solved the task in:
- 7 turns
- about 42.7s
- about $0.015
The harnessed run also passed verification, but it did so in a very different way:
- 12 turns
- about 566.9s
- about $1.06
- 12 outer invocations
- 12 rewrite decisions
maxInnerTurnsguardrail triggeredThe outer model repeatedly rewrote the context:
- early
injectrewrites to correct path confusion- repeated
compactrewrites to collapse read-heavy transcript clutter- more
injectrewrites to push the next step toward verificationFrom one angle, this is a success:
- the harness genuinely changed the trajectory
- the outer model had real control authority
- the transcript was being sculpted turn after turn
From another angle, it is an oversteering disaster:
- too many rewrites
- too much latency
- too much cost
- no timely terminate decision
- a guardrail had to stop the run
And yet the code still passed verification in the end.
Not only was the full harness run 70x (!!) more expensive than the inner-agent-only run, it also didn’t know when to stop, and ended up triggering the maxInnerTurns guardrail. Even though the code was already fixed! Codex was right that this was an “oversteering disaster.” Again, a complete failure from an engineering perspective, but kind of interesting from a research perspective.
So what did we learn from all this? Codex settled on two conclusions that I thought were interesting. First, the importance of intervention policy:
The interesting question is no longer:
Can an outer agent intervene?
The answer is obviously yes.
The interesting question is:What is the intervention policy that makes rewriting useful more often than harmful?
That is a much harder problem, and much more interesting than the original naive version of the idea.
And second, the biggest lesson is that “the prompt is the policy”:
In Demo 1, the outer agent was instructed to prefer
pass_throughwhile the inner agent still seemed to be making progress.In Demo 2, the outer agent was explicitly told to intervene when a rewrite could reduce wasted work or simplify the next turn.
That single policy change moved the system from:
to:
- “active context editor”
That is an important lesson for anyone building agent harnesses.
The control plane is not just infrastructure. It is behavior. The prompt is part of the policy surface.
And lastly, this summed it up well:
The interesting part is not that an outer agent can rewrite context.
The interesting part is that once you allow it, you have created a new control problem.
My takeaway? This could indeed be an interesting area for further research.
I think it’s quite likely that the current append-only conversation history approach continues to be the dominant approach for some time. But I have to wonder, if more and more inference moves from the “chat” paradigm to the “agent” paradigm, will we start to see approaches that fundamentally rethink what gets passed into the model as input?
I’m going to keep thinking about it, and maybe do some more “vibe research” in this area down the road.
If you want to dive deeper, I pushed the code and the markdown artifacts to a public Github repo:
Repo:
https://github.com/perceptiontheory/context-sculpting
Codex’s blog post draft:
https://github.com/perceptiontheory/context-sculpting/blob/main/blog_post_draft.md
Demo report:
https://github.com/perceptiontheory/context-sculpting/blob/main/demo_report.md
Original research plan:
https://github.com/perceptiontheory/context-sculpting/blob/main/research_plan.md
My favorite part from the research plan:
The key insight: the inner agent’s context window is not a log. It is a design space that the outer agent actively sculpts.
🔥 **What’s your take?**
Share your thoughts in the comments below!
#️⃣ **#Context #Sculpting #Perception #Theory**
🕒 **Posted on**: 1780793268
🌟 **Want more?** Click here for more info! 🌟