🚀 Check out this must-read post from Hacker News 📖
📂 **Category**:
💡 **What You’ll Learn**:
There’s a special kind of joy in watching a database do something heavy… without making your app threads cry.
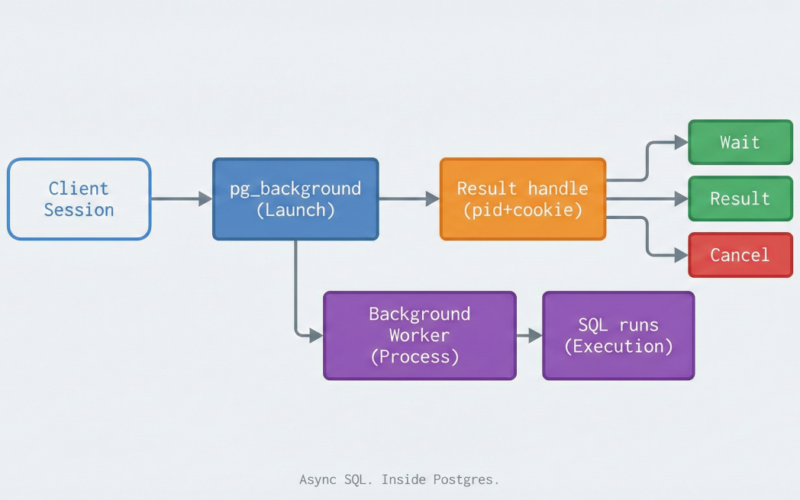
That’s the promise of pg_background: execute SQL asynchronously in background worker processes inside PostgreSQL, so your client session can move on—while the work runs in its own transaction.
It’s a deceptively simple superpower:
- Kick off a long-running query (or maintenance) without holding the client connection open
- Run “autonomous transaction”-style side effects (commit/rollback independent of the caller)
- Monitor, wait, detach, or cancel explicitly
- Keep the operational model “Postgres-native” instead of adding another job system
What pg_background is (and what it isn’t)
pg_background enables PostgreSQL to execute SQL commands asynchronously in dedicated background worker processes. Unlike approaches such as opening another connection (e.g., dblink) or doing client-side async orchestration, these workers run inside the server with local resources and their own transaction scope.
It’s not a full-blown scheduler. It’s not a queueing platform. It’s a sharp tool: “run this SQL over there, and let me decide how to interact with it.”
Why you’d want this in production
I’m opinionated here: most teams don’t need more moving parts. They need fewer, with better failure modes.
pg_background shines when you need:
- Non-blocking operations: launch long queries without pinning client connections
- Autonomous transactions: commit/rollback independently of the caller’s transaction
- Resource isolation & safer cleanup: worker lifecycle is explicit (launch / result / detach / cancel / wait)
- Server-side observability: list workers and see state/errors (v2)
Common production patterns:
- background VACUUM / ANALYZE / REINDEX
- async backfills or data repairs
- fire-and-forget audit/outbox writes
- “do the expensive part later” workflows (especially in OLTP-heavy apps)
The big deal: v2 API (recommended)
The project now strongly nudges new deployments toward the v2 API, which uses a (pid, cookie) handle to protect against PID reuse issues (a real-world footgun in long-lived systems).
From the repo docs, v2 brings: cookie-based identity, explicit cancellation vs detach, synchronous wait, and better monitoring via list functions.
Quick taste (v2)
That last point—detach is not cancel—is called out as an important semantic distinction.
Installation + one operational rule you shouldn’t ignore
Install is standard extension build + CREATE EXTENSION, but the “gotcha” is not subtle:
background workers consume max_worker_processes.
So size it intentionally.
The README walks through enabling the extension and setting max_worker_processes.
What’s new in the latest releases (v1.6 → v1.8)
If you haven’t looked recently: the project has had a meaningful “production hardening” arc.
v1.6 (released Feb 5, 2026): production stabilization + v2 API becomes the star
This release explicitly positions itself as “stabilizes pg_background for production use” and introduces the recommended v2 API with cookie-based worker handles.
Highlights include:
- v2 API with PID + cookie protection (safe against PID reuse)
- Improved DSM lifecycle handling
- Safer error handling & memory cleanup
- Better observability/diagnostics
- PostgreSQL 12–18 compatibility
Fixed items called out: NULL safety in error translation, race conditions in cleanup, memory context leaks in error paths, clearer error codes for cookie mismatches.
Known limitations that remain (still important in real deployments):
- Windows cancel limitations
- COPY protocol intentionally disabled
- transaction control inside workers not allowed
v1.7 (merged Feb 13, 2026): security + memory + CPU efficiency
v1.7 is where the internals got sharper edges sanded down—especially around handle security and long-running sessions.
Notable improvements listed in the v1.7 PR:
- cookie generation switched to pg_strong_random() (cryptographically secure) instead of predictable composition
- a dedicated WorkerInfoMemoryContext to avoid long-session memory bloat
- exponential backoff polling in wait/cancel loops to reduce CPU churn
- helper refactors + better constants/docs, plus explicit NULL checks around DSM creation
v1.8 (released Feb 13, 2026): operational controls + observability perks + packaging updates
The v1.8 release rolls up CI/packaging work and modernizes supported version stance: Docker-based CI refactor, tighter .gitignore, plus dropping PostgreSQL 13 and older to align with supported majors.
It also adds real operator-friendly features:
New in 1.8 (from the extension SQL and docs):
- pg_background_stats_v2() for session statistics
- pg_background_progress() + pg_background_get_progress_v2() for progress reporting
- new GUCs: pg_background.max_workers, pg_background.worker_timeout, pg_background.default_queue_size
- internal improvements called out: strong random cookies, dedicated memory context, exponential backoff polling, UTF-8 aware truncation, max-workers enforcement
And if you’re upgrading, the README’s compatibility table is blunt: PG 14+ is the current minimum supported line, with guidance to use older pg_background versions for older Postgres majors.
A practical checklist for using pg_background safely
Here’s the “don’t make tomorrow-you hate today-you” list:
- Use v2 unless you have a legacy dependency. PID reuse protection is worth it.
- Treat max_worker_processes as a capacity budget. Background work competes with everything else.
- Remember: detach ≠ cancel. Detach is “stop tracking”, not “stop running.”
- Design for one-time result consumption. Read results once; store them if you need replay.
- Use the new knobs (v1.8+): cap per-session workers, set timeouts, right-size queue memory.
- Use progress + stats for real operations. Observability prevents “mystery background gremlins.”
Closing thought
The best infrastructure is the kind that quietly does the work and refuses to be dramatic.
pg_background is that kind of tool: it gives PostgreSQL a clean, explicit async execution lane—now with safer handles (v2), stronger internals (v1.7), and operator-friendly controls and telemetry (v1.8).
If you want, paste your target use case (VACUUM jobs, backfills, “autonomous transaction” patterns, async ETL, etc.) and I’ll suggest a production-ready pattern with guardrails using the v2 API.
🔥 **What’s your take?**
Share your thoughts in the comments below!
#️⃣ **#Postgres #long #work #session #stays #light #Database #Technologies #Cyber #Security #Platform**
🕒 **Posted on**: 1771375192
🌟 **Want more?** Click here for more info! 🌟