
✨ Read this awesome post from Hacker News 📖
📂 **Category**:
✅ **What You’ll Learn**:
06-30-2026
This work was funded by Paradigm.
Transformers exhibit remarkable associative recall (AR) abilities: attention provides each token direct access to those preceding it, a mechanism that has been hard for other architectures, like recurrent neural networks (RNNs), to match.
But for some domains, we can’t afford the quadratic-attention overhead of transformers. One example is long-horizon RL, in the style of Dreamer. For these kinds of applications, we need to make recurrent neural networks work, but don’t want to give up on associative recall.
The best known RNN for associative recall is mLSTM, a variant of LSTM that maintains a matrix memory. mLSTMs demonstrate substantially improved recall over baselines on one benchmark, MQAR. But pure recall may not be sufficient to measure recurrent performance. In fields where environment transitions can be noisy, a useful proxy test is noisy associative recall (NAR).
Since MQAR doesn’t measure NAR, we can look at MAD’s noisy AR task suite. Here’s an example of what a task looks like:
0 9 3 10 12 13 15 14 0 9 5 8 2 9
Here, key 0 maps to value 9, key 3 maps to value 10, etc. The MAD generator uses distinct token ranges for keys, values, and distractors. So if keys are 0-5, then tokens 12-15 are distractors. A model good at NAR should predict 9 in the 10th position, having seen 0 -> 9 at the start, while ignoring the interleaved distractor tokens.
So how do we improve recurrent NAR? We can borrow some ideas from Muon, an optimizer that has been highly successful for language modelling. Muon orthogonalizes its momenta, acting as an equalizer of represented directions. It prevents a few strong directions from dominating the update, and lifts the weaker ones. Particularly relevant is recent research showing that Muon outperforms Adam in tail-end associative memory learning. The idea is that this equalization prevents weaker memories from being crowded out.
Inspired by this, we decided to test whether orthogonalizing the mLSTM memory matrix during reads, and training with this additional process, improves NAR performance.
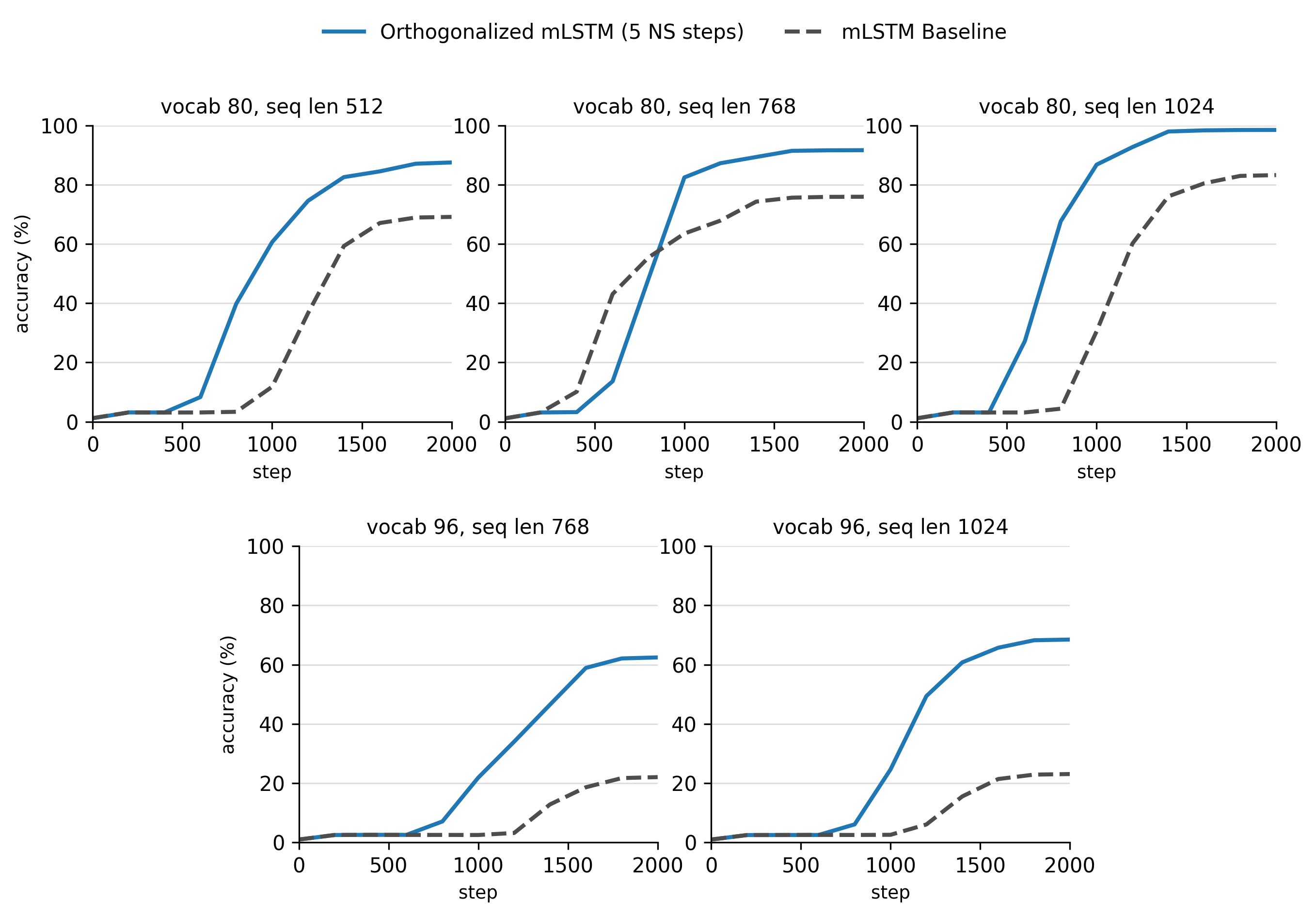
We compare mLSTM baselines to their orthogonalized variant on next-token prediction using MAD noisy AR samples. For training and evaluation we use MAD noisy-recall, with frac_noise set to 0.8 across a range of vocab sizes and sequence lengths. All models were trained using AdamW (betas = 0.9, 0.999, weight_decay = 0.01) for 2k steps at a batch size of 64. The learning rate was selected by sweeping 3e-4, 1e-3, 3e-3, and 1e-2 for each task setup.
We generate a new batch for training at each step, and maintain a separate fixed validation set per experiment. For orthogonalization, we normalize by the Frobenius norm (eps = 1e-6) and apply five Newton-Schulz iterations. We allow gradients to flow through the process. Crucially, we don’t write the orthogonalized memory back, as we found this degraded performance. We only use it for readouts. Fully reproducible code for our experiments can be found here.

$$
\small
\begin⚡⚡
\hline
\text💬 & \text🔥 & \text{Baseline} & \Delta \\
\hline
\text{vocab 80, len 512} & 87.5 \pm 12.4\ (20/24) & 69.1 \pm 17.8\ (17/24) & +18.4 \pm 18.1 \\
\text{vocab 80, len 768} & 91.7 \pm 11.4\ (22/24) & 75.9 \pm 12.0\ (13/24) & +15.7 \pm 16.8 \\
\text{vocab 80, len 1024} & 98.5 \pm 2.4\ (23/24) & 83.3 \pm 13.6\ (19/24) & +15.2 \pm 14.0 \\
\text{vocab 96, len 768} & 62.4 \pm 18.4\ (14/24) & 22.0 \pm 14.4\ (4/24) & +40.4 \pm 17.6 \\
\text{vocab 96, len 1024} & 68.5 \pm 18.3\ (16/24) & 23.1 \pm 15.3\ (4/24) & +45.4 \pm 18.6 \\
\hline
\end{array}
$$
We find that orthogonalization improves success rate and mean accuracy across the board. What’s interesting is that the gap seems to widen as we enter the vocab-96 regime, suggesting that orthogonalization helps most for difficult NAR tasks where raw mLSTMs struggle. In the latter two cases (vocab 96, seq len 768/1024), orthogonalization brings mLSTMs from the brink of failure (4/24 solved seeds) to substantially more reliable performance (14-16 solved seeds). This is striking for what we intended to be a small intervention. Newton-Schulz buys us additional gains at fixed parameter count, trading off additional FLOPs and wall-clock time.
We should be cautious not to read too much into these results. They hold in a small model regime, and NAR is a synthetic task. It would be worth investigating whether NAR gains translate into gains across real-world benchmarks for larger models.
Thanks to Dan Robinson, Alpin Yukseloglu and Glen Taggart for feedback and suggestions while writing this post.
{💬|⚡|🔥} **What’s your take?**
Share your thoughts in the comments below!
#️⃣ **#Matrix #Orthogonalization #Improves #Memory #Recurrent #Models**
🕒 **Posted on**: 1782884429
🌟 **Want more?** Click here for more info! 🌟