
✨ Discover this insightful post from TechCrunch 📖
📂 **Category**: AI,agentic ai,benchmarks,Exclusive,Mercor
✅ **What You’ll Learn**:
Last month I wrote about the new Merkur standard for measuring the capabilities of AI agents in professional tasks such as law and corporate analysis. At the time, the results were very poor, with every major lab scoring below 25%, so we concluded that lawyers were safe from being displaced by AI, at least for now.
But AI capabilities can change a lot in a couple of weeks.
This week’s release of Opus 4.6 has shaken up the leaderboards, with the new Anthropic model scoring nearly 30% in one-shot trials, and averaging 45% when given further optimizations in the problem. It’s worth noting that the release included a bunch of new agent features, including Agent Swarms, which may have helped with this type of multi-step problem solving.
Regardless, the result represents a huge leap from the previous state of the art, and a sign that progress in foundational modeling is not slowing down. “Jumping from 18.4% to 29.8% in just a few months is crazy,” said Mercure CEO Brendan Foody, who was particularly impressed.
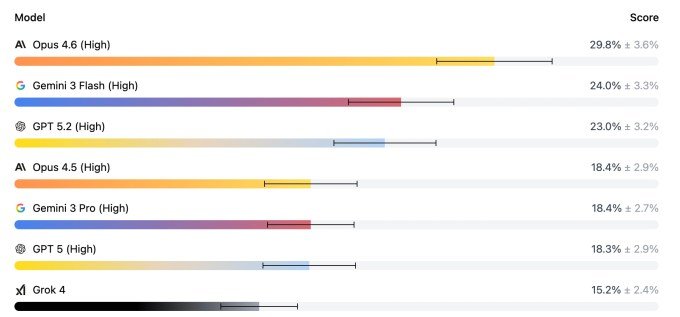
There’s still a long way to go to reach 30%, so it doesn’t look like lawyers need to worry about being replaced by machines next week. But they must be a lot less confident than they were last month!
💬 **What’s your take?**
Share your thoughts in the comments below!
#️⃣ **#agents #lawyers**
🕒 **Posted on**: 1770410163
🌟 **Want more?** Click here for more info! 🌟