
🔥 Check out this insightful post from Hacker News 📖
📂 **Category**:
📌 **What You’ll Learn**:
Executive Summary
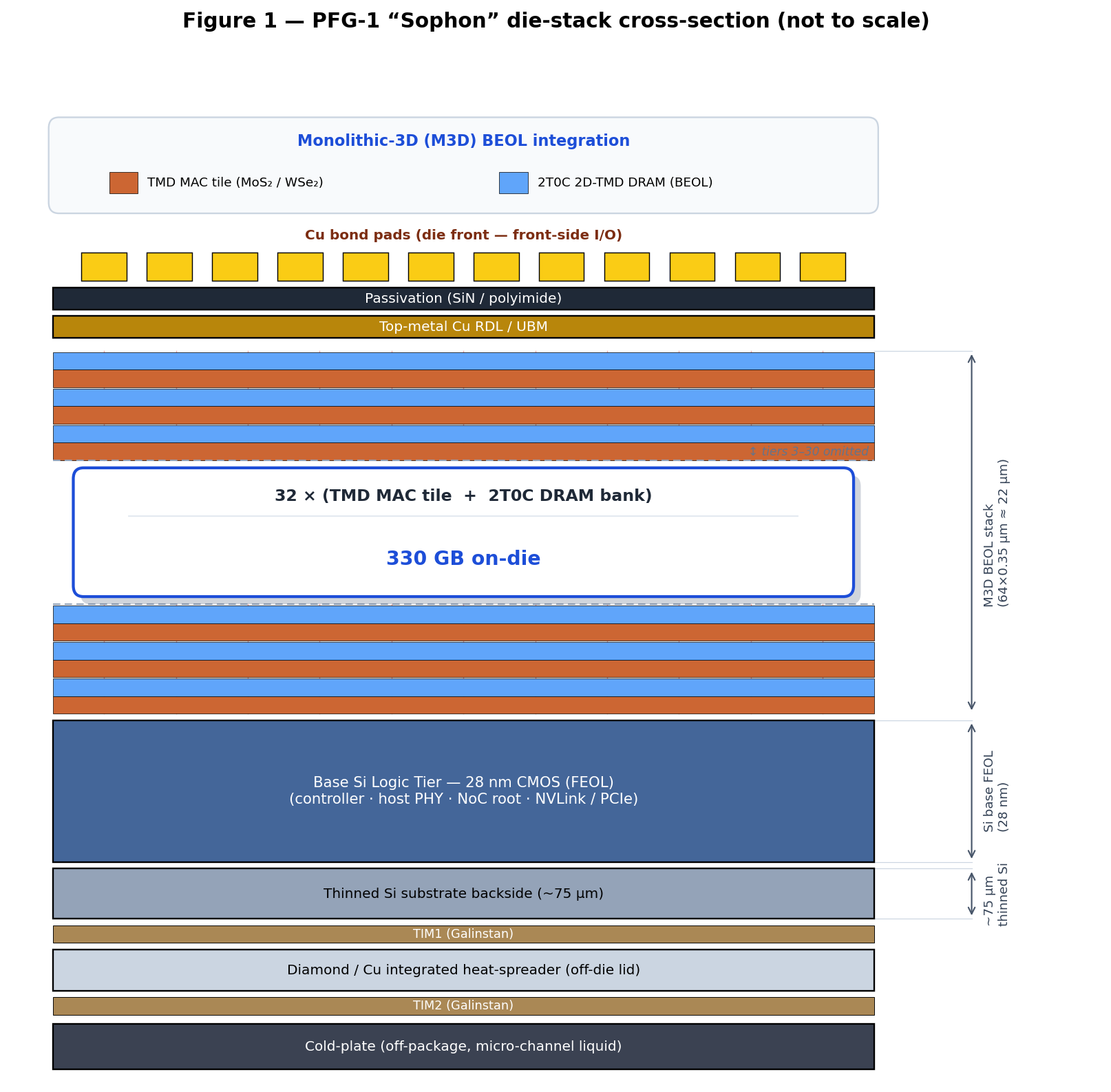
PFG-1 “Sophon” is a unified training-and-inference die on a 750 mm², 32-tier 2D
Transition-Metal Dichalcogenide (TMD) Monolithic 3D (M3D) platform. Weights, gradients, and optimizer state
reside in on-die 2T0C 2D-TMD gain-cell DRAM; because the array is fully read-write, the same silicon executes
BF16 forward/backward training passes and serves low-batch decode at the compute-bound rate.
Compute is pure digital Compute-In-Memory (CIM): each 256×256 DRAM subarray tile pairs a
binary sense amplifier with an 8-level adder tree, driven by a 500 MHz bit-serial activation broadcast. At
131,072 tiles/die this yields 4,200 TFLOPS FP8 and 2,100 TFLOPS BF16 in a
7.5 cm² footprint.
The die is built on a 28 nm Si Complementary Metal-Oxide-Semiconductor (CMOS) base tier, a 32-tier 2D-TMD CMOS
MAC stack, and a Monolithic Inter-tier Via (MIV) fabric [5][6][7], with the 2T0C DRAM module
embedded at the Back-End-Of-Line (BEOL) Metal-3 layer of each memory tier. The die stack cross-section is
shown in Figure 1.
| PFG-1 “Sophon” | |
|---|---|
| Memory | 2T0C 2D-TMD gain-cell DRAM |
| Compute paradigm | Pure digital CIM (sense amp + adder tree) |
| Target workload | Training (fwd + bwd + optimizer) and inference (decode + prefill) |
| Capacity | 330 GB |
| Compute | 2,100 TFLOPS BF16 (4,200 TFLOPS FP8 inference mode / 8,400 TOPS INT8) |
| Energy / MAC |
0.620 pJ (BF16 fwd) / 0.940 pJ (fwd + bwd) / 0.310 pJ (FP8 inference) |
| Peak efficiency | 3.72 TFLOPS/W (BF16 training avg.) |
| Tokens per watt |
38.7 tokens/s per W (80B FP8 decode, 373 W) — ~ 174× an NVIDIA Rubin (R200) or AMD Instinct MI455X at low batch (~ 0.22 tokens/s per W, HBM4-bound) |
| Active power | ≈ 379 W fwd / ≈ 749 W bwd (~ 564 W training avg.); 373 W FP8 decode |
| 80B model perf. | 2,406 tokens/s training, 0.23 J/tok; 7,219 tokens/s BF16 decode (14,438 tokens/s FP8 mode), 25.8 mJ/tok |
| 80B + INT4 + speculative (FP8 mode) | 72,188 tokens/s effective |
| BOM | $8,358 |
Sophon eliminates off-die High-Bandwidth Memory (HBM) entirely. For 80B-parameter BF16 training it fits
weights + first-order optimizer state fully on-die with ~ 10 GB of activation headroom for
gradient-checkpointed micro-batches; for inference it serves an 80B model at
7,219 tokens/s in native BF16 or the full 14,438 tokens/s in FP8 mode —
making it a single train-then-serve part that can be elastically repartitioned between training and serving
without changing hardware. Against an NVIDIA Rubin (R200) and an AMD Instinct MI455X — both 2026 HBM4 parts — Sophon delivers
~ 2.7–3.1× higher 80B batch-1 training throughput per die and ~ 48–53× higher
single-stream FP8 decode throughput, because both GPUs at low batch are HBM-bandwidth-bound at their HBM4
limits (Rubin 22 TB/s, MI455X 19.6 TB/s). Peak dense FLOPS favor the GPUs — Sophon BF16 dense is only ~ 0.21–0.24×
their peak — but peak FLOPS do not help at low batch, where weight-memory bandwidth governs.
The architecture delivers ~ 191–214× the weight bandwidth of an HBM4 package (191× vs Rubin,
214× vs MI455X) — a gap no HBM roadmap closes (Section 7).
The economics follow directly: Morgan Stanley puts a single NVIDIA VR200 (Rubin) NVL72 rack at
≈ $7.8M — HBM memory alone ≈ $2.0M (25.7% of the rack, +435% over GB300). Sophon
eliminates that line item, for a ~ 9.9× / 11.6× lower hardware BOM than a Rubin / MI455X
[17].
1. Introduction & Motivation
Modern AI accelerators face a memory wall on both workloads they must serve:
Inference is read-dominated. The model weights are fixed at deployment; every decode
step reads the full weight tensor once per generated token. The key metrics are read energy per bit, idle
leakage (the model must stay resident between requests), and weight-fetch bandwidth at low batch. Conventional
High-Bandwidth Memory (HBM) is bandwidth-bound at low batch: every token’s MAC traffic serializes through the
~ 22 TB/s (Rubin) / 19.6 TB/s (MI455X) HBM4 path, and a 288–432 GB HBM4 subsystem draws ~ 10–15 W in self-refresh just to keep the model
resident.
Training is read-write symmetric. Every forward pass reads weights; every backward
pass writes gradient updates; the optimizer updates weights in place each step. In-place writability, low
write energy, and capacity for both weights and optimizer state are critical. A non-volatile
inference-only memory cannot train — for example, Single-Level Cell (SLC) Resistive RAM endurance caps at ~10⁶
cycles, while training an 80B model requires ~10¹⁰ write cycles per parameter.
A 2T0C 2D-TMD gain-cell DRAM solves both problems with one cell. It exploits the anomalously
low off-current density (Joff ≈ 10⁻¹⁵ A/µm = 1 fA/µm at 28 nm, i.e. ≈ 0.5 fA per cell) of TMD
transistors to obtain multi-second retention without an explicit storage capacitor, enabling
in-place gradient writes at 20 fJ/bit with unlimited write endurance and a refresh overhead
of only ≈ 0.08 W. Because the storage node is writable on every cycle, the same die that serves inference can
also train; because retention is seconds-long, idle power collapses to ~ 3 W — an inference-grade idle profile
on a fully writable training die.
PhantaField’s 2D-TMD M3D platform integrates this DRAM module at the BEOL Metal-3 layer of each memory tier,
directly above the logic tier whose MAC array consumes its weights.
2. Architecture Overview
A. Platform
Sophon uses the following physical stack:
| Tier(s) | Function | Process |
|---|---|---|
| Base (Si) | Controller, NoC root, host I/O, PCIe/NVLink PHY | 28 nm bulk Si CMOS |
| Tiers 1 – 32 |
Interleaved 2D-TMD stack: 32 logic tiers (MAC array, 750 mm² each) alternating with 32 memory tiers (2T0C DRAM bank, 750 mm² each), forming 32 logic-plus-memory doublets |
BEOL 2D-TMD (MoS₂ n-FET / WSe₂ p-FET) on odd tiers + DRAM module on even tiers |
| Lid | Cu / CVD-diamond heat spreader | optional; enables two-side cooling |
Total stack height: ~22 µm above the Si die (64 tiers × 0.35 µm/tier). The 90 nm-pitch MIV
grid provides 1.23 × 10⁸ slots/mm² available inter-tier connections; the design populates only ~5.5 ×
10⁵/mm², leaving > 99% MIV headroom.
Tiers are not split within a single layer; instead the 64-tier stack
interleaves dedicated logic and memory tiers in an A/B/A/B… repeating pattern. Two adjacent
tiers form one logic-plus-memory doublet; the stack contains 32 such doublets:
-
Logic tiers (32 × 750 mm² = 24,000 mm² total MAC area): 2D-TMD CMOS MAC array on
odd-indexed tiers — MoS₂ n-FETs for NMOS, WSe₂ p-FETs for PMOS. Density 0.175 TFLOPS FP8/mm² (0.0875
TFLOPS BF16/mm²). Clocked at 1.2 GHz, Vdd = 0.6 V. -
Memory tiers (32 × 750 mm² = 24,000 mm² total memory area): 2T0C 2D-TMD DRAM on
even-indexed tiers, fabricated at the Metal-3 BEOL of that tier. Each memory tier sits directly above its
paired logic tier; vertical Monolithic Inter-tier Vias (MIVs) on a sub-100 nm pitch carry
bit-line/word-line/sense signals straight up from the logic MAC array into the cells, giving every MAC its
own private vertical port to local weights with zero NoC traffic. This interleaved arrangement preserves
the same total area and capacity as a hypothetical in-tier 50/50 split, while doubling the per-tier MAC
routing area and shortening MAC-to-cell signal paths to a single tier-pitch of 0.35 µm.
Why 2D TMD? TMD CMOS (MoS₂ / WSe₂) is the only transistor technology that simultaneously
offers: (1) BEOL-compatible growth at ≤ 450 °C [6]; (2) atomic-scale
channel thickness eliminating short-channel leakage [1][2]; (3) electron mobility ≥ 120 cm²/V·s
[4]; and (4) intrinsic radiation hardness (no buried-oxide trap volume).
Critically, the TMD off-current density Joff ≈ 10⁻¹⁵ A/µm (1 fA/µm) at 28 nm — i.e. ≈ 0.5 fA for
a 0.5 µm-wide cell transistor, roughly 4 orders of magnitude lower than Si NMOS at equivalent gate length
[2][3] — is what enables a 2T0C cell to
retain data for seconds without any storage capacitor [8][9], keeping the cell area at 8 F² rather than the ~20 F² needed for a
conventional 1T1C DRAM.
B. PFG-1 “Sophon” — 2T0C DRAM die
Sophon places a 2T0C 2D-TMD gain-cell DRAM (8 F², 1 bit/cell) at the Metal-3 BEOL of each
memory tier. The cell structure is shown in Figure 2 and consists of:
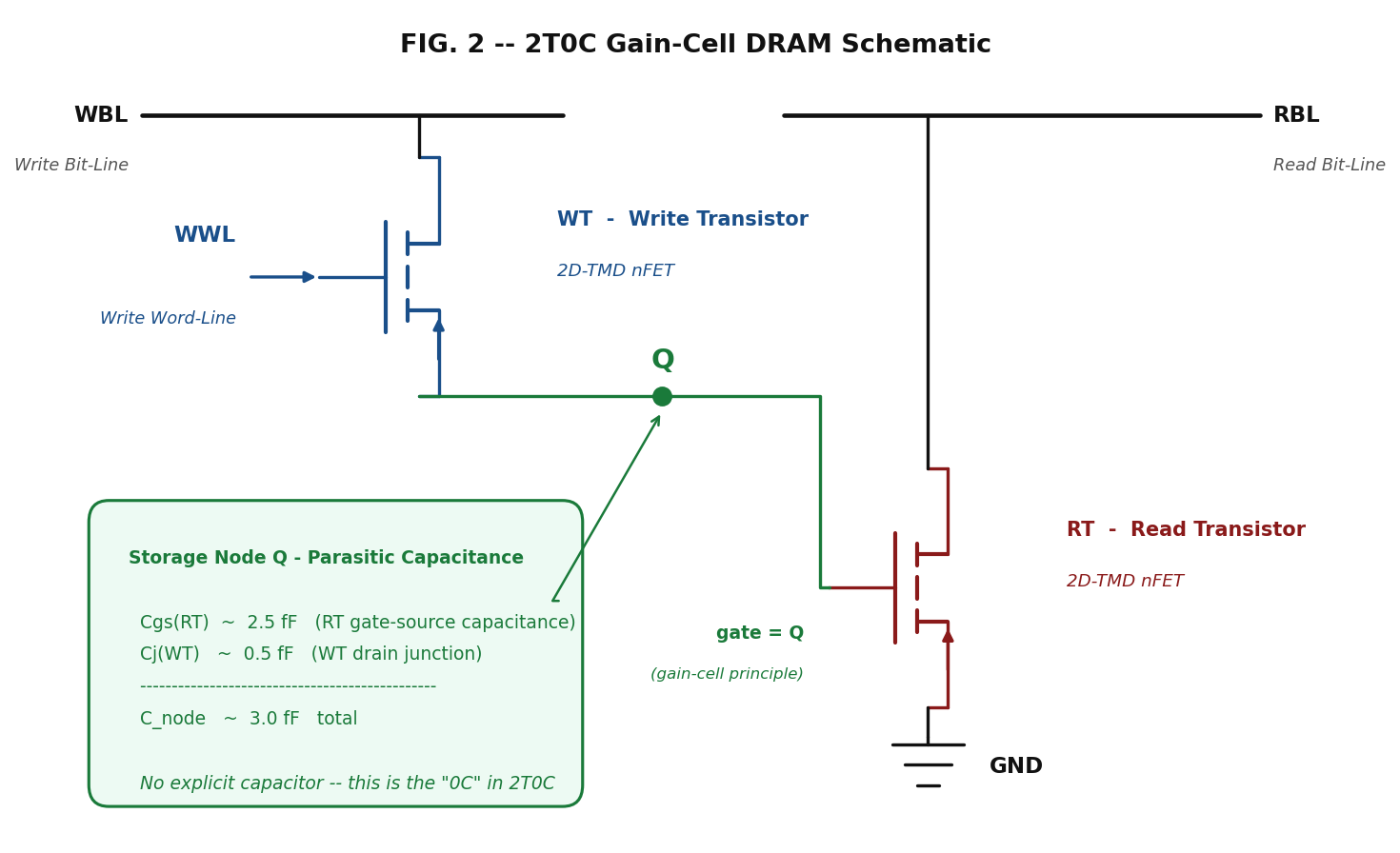
-
Write Transistor (WT): a TMD nFET gated by the Write Word-Line (WWL), which charges the
storage node to Vdd or discharges it to GND. -
Read Transistor (RT): a TMD nFET whose gate is the storage node; its drain current
indicates the stored bit. -
Storage node: the parasitic gate capacitance of RT (~2.5 fF at 28 nm TMD) plus the
junction capacitance of WT’s drain (~0.5 fF). No explicit Metal-Insulator-Metal (MIM) or trench capacitor
— that is the “0C” in 2T0C.
The TMD off-current density of 1 fA/µm (Ioff ≈ 0.5 fA for a 0.5 µm cell transistor) gives
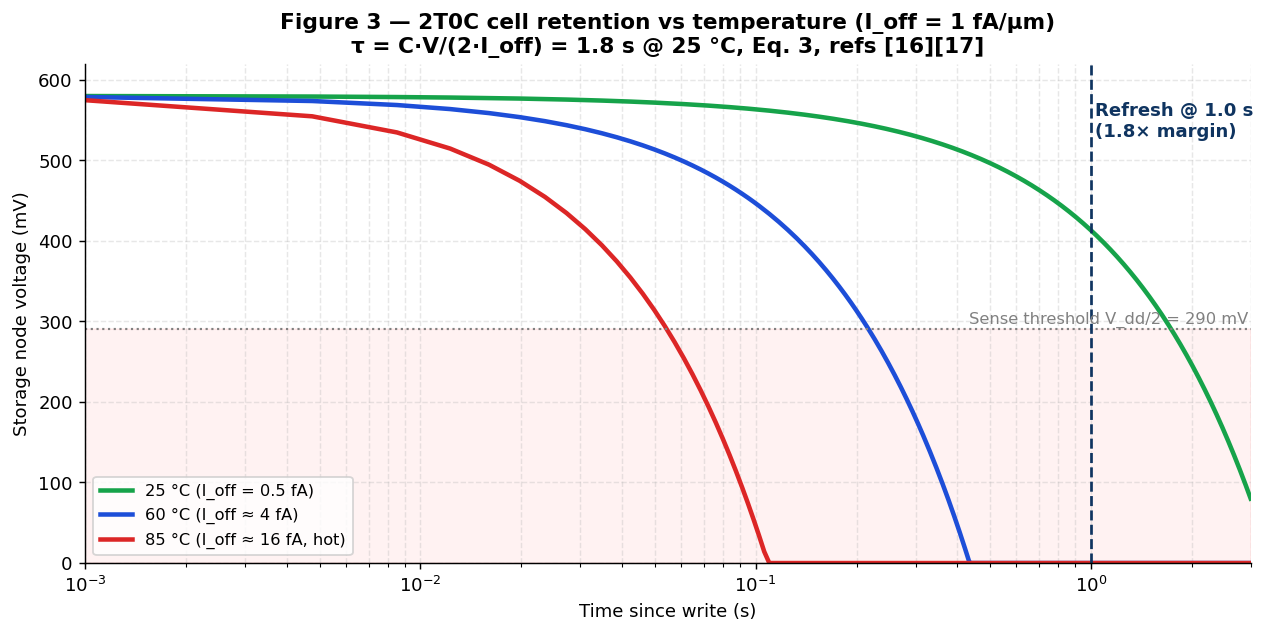
retention τ = C·Vdd / (2·Ioff) = 1.8 s at 25 °C
[8][9] — see Eq. 3 and
Figure 3 for the retention curve. Sophon refreshes every 1.0 s (1.8×
margin), consuming only ≈ 0.08 W for the full 330 GB die (Eq. 4).
Retention derates ≈ 2× per 10 °C; above 60 °C junction temperature, on-die thermal sensors shorten the
refresh interval (≈ 159 ms at 60 °C, ≈ 28 ms at 85 °C), with refresh power staying below ~ 4 W even in the
hot corner.
Because the storage node is writable on every cycle, Sophon supports in-place BF16 gradient accumulation
with unlimited endurance — exactly what training requires — while the same array, read-only, serves the
inference decode loop. The die loads a model once and either serves it (inference) or updates it in place
(training); a powered-off die reloads its weights from off-die Non-Volatile Memory express (NVMe) at boot
(§11.2).
C. Die Floorplan & On-Die System Organization
The 131,072 CIM tiles are not a flat array — they are partitioned across the 32 logic tiers of the stack
(§2.A), exactly 4,096 tiles per logic tier (derived: 131,072 ÷ 32). Each tile occupies a
fixed cell on its tier and is the atomic unit of compute, storage, and redundancy: a 256×256 weight subarray
(65,536 weights) feeding a binary sense amp and an 8-level adder tree, with bit-serial activation broadcast
at 500 MHz (16 cycles BF16, 8 cycles FP8). The weights for every tile live in the 2T0C cells of the memory
tier directly above it (§2.B), so a tile is physically a vertical logic-plus-memory column, not a planar
block. A tier is therefore a 4,096-tile mesh of these columns; the full die is 32 such meshes stacked at
0.35 µm pitch, with the 28 nm Si base below carrying everything that is not compute.
The NoC is a per-tier 2D mesh, not a global fabric. Each logic tier runs its own mesh
router fabric at ≈ 290 TB/s bisection, and the 64 tiers together present
18,560 TB/s aggregate (derived: 290 × 64). What rides the NoC is deliberately minimal:
activations and partial sums — the operands that must move between tiles to assemble a
layer’s output across the 4,096-tile fan-in. Weights never touch the NoC. Every weight is
read through its tile’s private vertical MIV port — a single tier-pitch hop straight down from the cell to
its MAC — delivering 4.2 PB/s of in-tile weight bandwidth with zero shared-bus contention (§2.A). This is
the load-bearing asymmetry of the floorplan: the multi-petabyte traffic (weight fetch) is kept entirely
vertical and local, so the lateral NoC only ever carries the comparatively small activation/partial-sum
flux. The base-tier NoC root stitches the per-tier meshes together and bridges them to the
controller and host I/O, but it is never in the weight path.
Each tile additionally owns a small SRAM scratchpad for activations. Because the NoC
carries activations and partials rather than weights, the scratchpad is where a tile stages its inbound
activation vector, accumulates its slice of the partial sum across the bit-serial broadcast, and buffers the
outbound result before it is handed to the mesh. Holding the live activation working set in fast local SRAM
— adjacent to the adder tree, not in the 2T0C DRAM — keeps the broadcast/accumulate inner loop entirely
on-tile and lets the 1 Hz-refresh gain-cell DRAM (§2.B) stay dedicated to weights and KV cache, whose access
pattern is read-mostly and latency-tolerant by comparison.
Clock and power are delivered down the 22 µm stack to a low-voltage rail. The logic tiers
are clocked at 1.2 GHz from a base-tier clock root distributed upward through the MIV grid;
the bit-serial activation broadcast runs on a separate 500 MHz domain. Operating at
Vdd = 0.6 V is what makes a 64-tier monolithic stack thermally viable — dynamic
power scales with Vdd², so the 0.6 V rail draws ≈ 2.8× less energy than a nominal 1.0 V CMOS rail
at the same activity. The trade is current: at fixed power, lowering the voltage raises the supply current,
and that current must reach every tier through a power-delivery network (PDN) that climbs the full ~22 µm of
stack. Because the design leaves > 99% of the MIV grid unused for signaling (§2.A), those spare vias can
be allocated to the PDN (derived) — parallel Vdd/GND vias carried straight up to each logic tier
hold IR-drop in check across the stack while the bit-serial broadcast switches thousands of tiles in
lockstep.
The 28 nm Si base tier is the system’s front door. It carries the controller, the NoC root,
host I/O, and the PCIe/NVLink-class PHY — all in mature bulk-Si CMOS, where high-speed analog SerDes and
large I/O drivers belong, rather than in the BEOL 2D-TMD tiers above. This separation is what lets the same
die both serve and train without hardware change: the host loads a model once through the
base-tier PHY into the on-die 2T0C DRAM, after which the controller either drives the inference decode loop
(weights read-only) or runs in-place gradient writes for training (§2.B) — and a fleet repartitions between
the two by command, not by re-spinning silicon. An 80B model — weights, optimizer state, activations, and KV
cache — resides entirely on the single die, with every MoE expert resident on-die and only the routed
experts drawing power.
| Resource | Per logic tier | Per die (×32 tiers) |
|---|---|---|
| CIM tiles | 4,096 (derived) | 131,072 |
| Weight subarray / tile | 256×256 = 65,536 weights; binary sense amp + 8-level adder tree | |
| Die footprint | single 750 mm² die — 64 tiers stacked at 0.35 µm (~22 µm tall) | |
| Logic (MAC) silicon | 750 mm² / tier | 24,000 mm² cumulative (32 × 750, §2.A) |
| On-die 2T0C DRAM | 750 mm² / tier | 330 GB total (weights + optimizer + KV cache) |
| NoC mesh bisection | ≈ 290 TB/s | 18,560 TB/s aggregate over 64 tiers |
| In-tile weight BW (vertical MIV) | 4.2 PB/s — never crosses the NoC | |
| Activation store | Per-tile SRAM scratchpad (NoC carries activations + partial sums) | |
| Clock / rail | 1.2 GHz logic, 500 MHz broadcast; Vdd = 0.6 V | |
| Base tier | 28 nm Si — controller, NoC root, host I/O, PCIe/NVLink-class PHY | |
3. Physical Calculations
All formulas are derived in the Equations Appendix (§13). Numeric values reference the
equation number in that appendix.
3.A. Cell Geometry & Per-Tier Density
The 64-tier stack interleaves dedicated logic and memory tiers in an A/B/A/B… repeating
pattern: 32 logic tiers (odd-indexed) and 32 memory tiers (even-indexed), forming 32 logic-plus-memory
doublets. Each individual tier uses its full 750 mm² footprint for its single role: a logic
tier holds the 2D-TMD MAC array (750 mm² MAC); a memory tier holds the co-located 2T0C DRAM bank (750 mm²
memory). All capacity and throughput numbers below are reported on a per-doublet basis (one
logic tier + one memory tier) so they remain directly comparable to the legacy per-tier presentation.
A.1 PFG-1 “Sophon” — 2T0C 2D-TMD gain-cell DRAM weight/gradient cell
The 2T0C gain cell consists of two 2D-TMD transistors and zero explicit storage capacitors
[8][9][10]. It exploits the anomalously low off-current of TMD field-effect
transistors — a width-normalized density of Joff = 10⁻¹⁵ A/µm (1 fA/µm) at 28 nm
[2][3], i.e. only
≈ 0.5 fA for a 0.5 µm-wide Read Transistor — to retain charge on the gate parasitic of the
Read Transistor (RT) for seconds without a Metal-Insulator-Metal (MIM) or trench capacitor.
Cell structure:
-
Write Transistor (WT): TMD nFET, gate driven by the Write Word-Line (WWL). Drives the
storage node to Vdd (write “1”) or GND (write “0”). -
Read Transistor (RT): TMD nFET, gate = storage node, source grounded, drain = Read
Bit-Line (RBL). When storage = Vdd, RT conducts; when storage = 0, RT is off. Binary current
sense. -
Storage node: parasitic Cgs of RT (~ 2.5 fF) + Cjunction of WT
drain (~ 0.5 fF) = ~ 3.0 fF total. No explicit capacitor — that is the “0C” in 2T0C.
Retention physics (Eq. 3, derived from
[8]): τ = Cnode · Vdd / (2 · Ioff). At
Cnode = 3.0 fF, Vdd = 0.6 V, and Ioff = Joff · WRT =
1 fA/µm × 0.5 µm = 0.5 fA at 25 °C, τ = 1.8 s. Sophon refreshes every
1.0 s (1.8× margin). Retention derates ≈ 2× per 10 °C; above 60 °C junction temperature,
on-die thermal sensors shorten the refresh interval (≈ 159 ms at 60 °C, ≈ 28 ms at 85 °C).
| Parameter | Value | Notes |
|---|---|---|
| Cell footprint | 8 F² | 2T0C (WT + RT), no capacitor [10] |
| Bits per cell | 1 (digital) | Binary gate state |
| Periphery overhead | 45% | Sense amp + refresh controller [8] |
| Planar density | 110.0 Mb/mm² | Eq. 1: 1 / (8 × 28² nm² × 1.45) |
| Read energy | 30 fJ/bit | BL precharge + current sense [28] |
| Read latency | 3 ns | Cell access + current sense |
| Write energy | 20 fJ/bit | WT channel charge transfer [28] |
| Write endurance | unlimited | Gain-cell DRAM — charge-based, no wear-out mechanism [10] |
| Retention | 1.8 s @ 25 °C | Refresh every 1.0 s (Eq. 3); Ioff = 1 fA/µm × 0.5 µm |
| Static / refresh power | ≈ 0.08 W (refresh) | Full 330 GB refreshed at 1 Hz (Eq. 4); ~1 W budgeted warm |
Why a capacitor-less gain cell? A conventional 1T1C DRAM needs a ~ 20 F² trench/MIM
capacitor that is incompatible with low-temperature BEOL M3D integration. The 2T0C cell stores charge on the
Read Transistor’s own gate parasitic, so it is built entirely with the same TMD transistors used in the MAC
array — no separate capacitor module, no third-party Intellectual Property (IP) license — and the
multi-second retention enabled by the 1 fA/µm off-current makes refresh power negligible (≈ 0.08 W,
Eq. 4).
A.2 Per-doublet and per-die capacity
The stack contains 32 doublets (one logic tier + one memory tier per doublet). Each doublet
contributes one logic-tier’s MAC area and one memory-tier’s storage area; the total active MAC area and
memory area are therefore identical to a hypothetical 64-tier in-tier-split presentation, but routing is
denser because each logic tier no longer competes for footprint with its memory bank.
| Item | PFG-1 Sophon (2T0C DRAM) |
|---|---|
| Memory area per memory tier | 750 mm² |
| Logic area per logic tier | 750 mm² |
| Memory tiers / logic tiers | 32 / 32 |
| Capacity per doublet | 10.31 GB |
| Total capacity (32 doublets) | 330 GB |
| FP8 throughput per logic tier | 131.25 TFLOPS |
| BF16 throughput per logic tier | 65.6 TFLOPS |
| FP8 throughput (32 logic tiers) | 4,200 TFLOPS |
| BF16 throughput (32 logic tiers) | 2,100 TFLOPS |
| INT8 throughput (32 logic tiers) | 8,400 TOPS |
Sophon holds 330 GB. For training, an 80B-parameter BF16 model (160 GB) plus first-order
optimizer state (160 GB for SGD-momentum or Lion) = 320 GB, leaving
10 GB for gradient-checkpointed activations (Section 5.B.2). For
inference, an 80B BF16 model (160 GB) leaves 170 GB free, or an 80B FP8 model (80 GB)
leaves 250 GB free for an extended Key-Value (KV) cache or a co-resident draft model (Section 5.A).
A.3 Gain-Cell Read/Write Operation & Sense Margin
Sections A.1 and §2.B describe the structure of the 2T0C cell; this subsection describes how it is
operated cycle-by-cycle. The two-transistor topology decouples the write path from the read path
entirely — the Write Transistor (WT) owns the storage node, the Read Transistor (RT) only senses it — which
is precisely what enables the same array to stream weights to the MAC on every cycle while remaining
in-place writable for gradient accumulation (§3.C).
Write. A write asserts the Write Word-Line (WWL), turning the WT on and connecting the
storage node (RT gate parasitic ~2.5 fF + WT drain junction ~0.5 fF ≈ 3.0 fF) to the Write Bit-Line. The WT
channel then charges the node to Vdd = 0.6 V for a “1” or discharges it to GND for a “0”; WWL is
de-asserted and the TMD off-current (≈ 0.5 fA per 0.5 µm cell) traps that charge for the full retention
window. The transferred charge is Cnode · Vdd ≈ 3.0 fF × 0.6 V, and the measured write
energy is 20 fJ/bit — a single channel charge-transfer event, with no high-voltage charge
pump and no oxide stress. Because both the value being written and the in-place gradient update (§3.C) take
this identical path, training and inference share one write primitive.
Read — the gain-cell mechanism. The defining property of the cell is that
RT’s gate is the storage node, so the stored level directly modulates RT’s drain
conduction. To read, the Read Bit-Line (RBL) is precharged and RT’s drain is enabled: a stored Vdd
turns RT on and sinks current; a stored GND leaves RT off. A binary sense amplifier on the
RBL resolves the resulting current into a digital bit in ≈ 3 ns at 30 fJ/bit. Critically,
this is a non-destructive read: RT senses the node as a gate voltage and draws no
charge out of it — unlike a 1T1C cell, where the read dumps the storage capacitor onto the bit-line by
charge-sharing and the bit must be written back before the next access. With no write-back cycle, the array
can be read back-to-back every cycle, which is exactly how it feeds the 500 MHz bit-serial activation
broadcast and the 4.2 PB/s in-tile weight bandwidth (§3.B) without ever stalling for restore.
Sense margin & why sensing is digital. The read window is set by RT’s on/off
drain-current ratio. The same 1 fA/µm TMD off-current that gives multi-second retention also collapses the
“0” leg of the read to the sub-femto-amp floor, while the “1” leg conducts at the full TMD on-current — an
on/off ratio of many decades. That enormous, deterministic separation means the sense amp only ever has to
decide “conducting vs. not,” so a single current-comparator threshold suffices:
no ADC, no DAC, no reference ladder. This is what keeps the read path pure-digital and
deterministic end-to-end — there is no analog accumulation to quantize, consistent with the ADC-free CIM
tile architecture (§3.D).
Disturb, retention & endurance during operation. Because a read is gate-voltage sensing
through RT and never discharges the node, read-disturb is negligible — a cell can be read
arbitrarily many times between refreshes with no charge loss, so the refresh cadence is governed solely by
leakage, not by access traffic. Retention τ = Cnode · Vdd / (2 · Ioff) =
1.8 s at 25 °C fixes the 1 Hz refresh (1.8× margin, ≈ 0.08 W for 330 GB;
see A.1). Writes are likewise benign: the bit is set by gate-controlled charge transfer through the WT, with
no oxide tunneling and no filament formation, so there is no wear-out mechanism and
endurance is effectively unlimited — the enabling condition for streaming in-place gradient
writes throughout a full training run (§3.C).
| Property | 2T0C TMD gain cell (Sophon) | Conventional 1T1C DRAM |
|---|---|---|
| Read type | Non-destructive (RT gate-voltage sense) | Destructive (capacitor charge-share onto BL) |
| Write-back after read | None — read back-to-back every cycle | Required every access (restore) |
| Storage element | RT gate parasitic + WT drain junction (≈ 3.0 fF, “0C”) | Explicit MIM / trench capacitor |
| Sensing | Binary current comparator — no ADC/DAC | Differential charge-sensing amp + reference |
| Cell area | 8 F² | ≈ 20 F² (capacitor-dominated) |
| Write endurance | Unlimited (gate-controlled charge, no oxide wear) | Unlimited, but every read costs a restore write |
3.B. Bandwidth Model
Because weights live in memory co-located with their consuming MAC, there is
no global weight-bandwidth pipe. Sophon employs
fully digital Compute-In-Memory (CIM) — a sense-amplifier and binary adder tree per
column-group. Bandwidth decomposes into orthogonal contributions.
B.1 Weight bandwidth (memory → local MAC)
Each BF16 MAC reads 16 bits from the DRAM bank directly above its tile at 30 fJ/bit with 3 ns latency. The
bit-serial multiply runs at the 500 MHz wordline rate over 16 cycles for BF16 (8 cycles in FP8 inference
mode); the per-column sense amplifier produces a 1-bit partial product per cycle that feeds an 8-level
binary adder tree. A 4-stage pipeline hides DRAM latency.
| Quantity | BF16 (native) | FP8 (inference mode) |
|---|---|---|
| MAC throughput | 2,100 TFLOPS | 4,200 TFLOPS |
| Weight bits per MAC | 16 bits (BF16) | 8 bits (FP8) |
| Aggregate weight BW | 4.20 PB/s | 4.20 PB/s |
| Per-tile read width | 275 bits/cycle | 550 bits/cycle |
| Memory read latency | 3 ns (4 cycles) | 3 ns (4 cycles) |
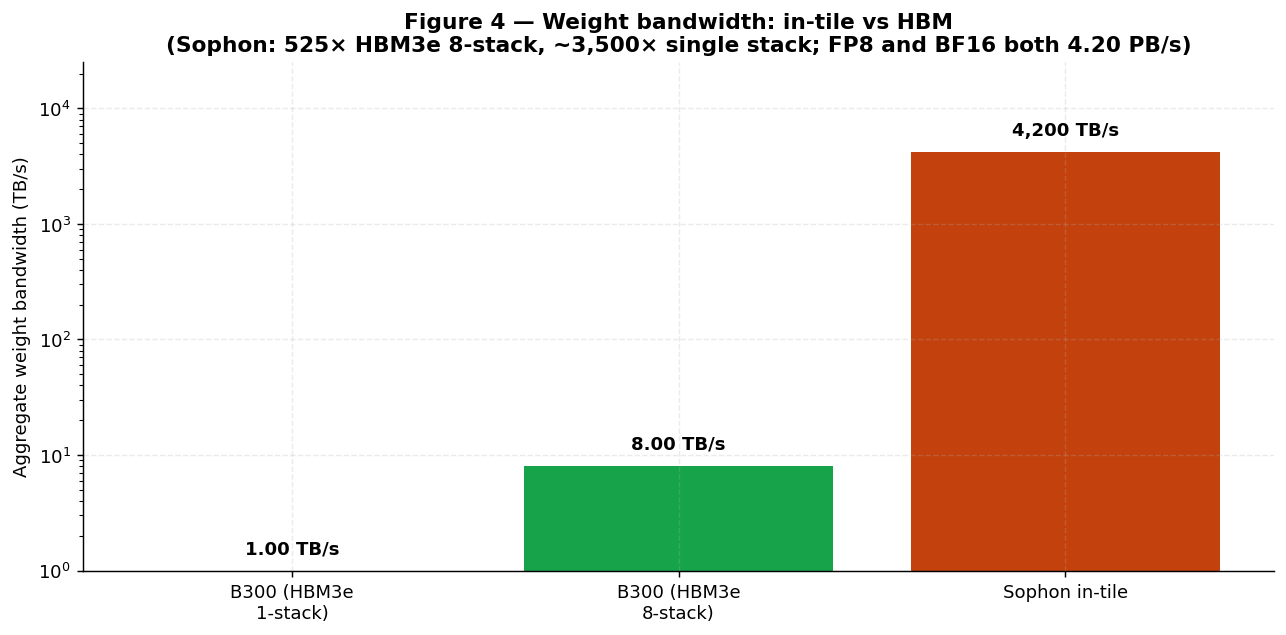
Sophon delivers 4.20 PB/s of aggregate weight bandwidth in either datatype — the byte-rate
of weight consumption is the same: 2 bytes/BF16-MAC at 2,100 TFLOPS, or 1 byte/FP8-MAC at 4,200 TFLOPS, both
producing 4.20 PB/s. This bandwidth is in-tile and never crosses the Network-on-Chip (NoC).
Why is weight bandwidth independent of datatype and of capacity? In a Compute-In-Memory
architecture, weight bandwidth is set by the MAC array’s weight-consumption rate, which is
intrinsic to the logic tiers, while capacity is set by the
memory-tier areal density (110.0 Mb/mm² for 2T0C DRAM, §3.A). Because every weight is physically
co-located with the MAC that consumes it, there is no shared bus whose width would scale with total stored
bytes or with bit-depth: a higher-bit datatype simply reads more bits per MAC at a proportionally lower
MAC rate. The bandwidth equality is therefore a direct consequence of
BW = (bytes per MAC) × (MAC rate)being identical for both modes (1 B × 4,200 TFLOPS = 2 B ×
2,100 TFLOPS = 4.20 PB/s).
B.2 Gradient bandwidth (training write path)
During the backward pass, accumulated gradients are written back to the DRAM bank at 20 fJ/bit:
| Quantity | Value |
|---|---|
| Gradient write bandwidth | 4.20 PB/s (mirrors weight read BW) |
| Write energy per BF16 gradient | 20 fJ × 16 bits = 320 fJ = 0.32 pJ |
| Backward-pass write power (55% util.) | 370 W |
| Backward-pass write power (100% util.) | 672 W |
Inference uses the read path only and incurs none of this write power.
B.3 Activation bandwidth (per-tile SRAM scratchpad)
Activations occupy a small per-tile SRAM scratchpad (SPM) (5% of tier area, ~37.5 mm²/tier, ~0.7 GB/tier):
- Per-tier activation bandwidth: ~11,000 GB/s aggregated
- Total activation bandwidth: ~700 TB/s
B.4 NoC bandwidth (inter-tile)
A 2-D mesh NoC routes activations and control. Each tier has its own mesh; vertical MIVs carry inter-layer
activations.
| Path | Bandwidth |
|---|---|
| Per-tier NoC bisection | 290 TB/s |
| Aggregate NoC (64 tiers) | 18,560 TB/s |
| MIV vertical fabric (weight delivery) | 4,200 TB/s sustained |
B.5 Bandwidth summary
| Path | Sophon | Notes |
|---|---|---|
| Weight (memory → MAC) | 4.20 PB/s | In-tile |
| Gradient (MAC → memory) | 4.20 PB/s | In-tile, bwd pass only |
| Activation (NoC) | 18,560 TB/s | Inter-tile |
| Inter-tier (MIV) | 4,200 TB/s | Vertical (= in-tile weight BW) |
| HBM3e reference (8-stack) | 8.0 TB/s | Off-package (NVIDIA Rubin R200) |
| HBM4 reference (NVIDIA Rubin R200, 8-stack) | 22 TB/s | Off-package |
| HBM4 reference (AMD Instinct MI455X, 8-stack) | 19.6 TB/s | Off-package |
Sophon provides ~ 191× more weight bandwidth than NVIDIA Rubin (R200) and
~ 214× more than AMD Instinct MI455X (4,200 TB/s vs 22 TB/s for an 8-stack HBM4 package on
Rubin, and 19.6 TB/s for an 8-stack HBM4 package on MI455X
[16][18]) — because that bandwidth is
intrinsic to the storage location, not a separate interconnect. Figure 4 plots the
comparison.
3.C. Per-MAC Energy & Power Envelope
C.1 Energy per MAC operation
Convention note: throughout this paper, “2,100 TFLOPS BF16” and “4,200 TFLOPS FP8” count each
multiply-accumulate (MAC) as 2 floating-point operations (one mul + one add)
[16]. Energies tabulated below are stated per MAC (per
weight processed), so per-FLOP figures are half the listed values. The chip-power calculations in §C.3 use
the per-FLOP convention to align with the TFLOPS rates.
Architecture note: Sophon uses pure digital Compute-In-Memory (CIM). Each tile contains
a per-column sense amplifier feeding an 8-level binary adder tree that produces the partial sum for one
row of a 256×256 weight subarray. All multiply-accumulate arithmetic is performed in the binary domain
with full deterministic 16-bit (BF16) or 8-bit (FP8) precision — see §3.D for the digital-CIM tile
walkthrough and §3.D.2 for why this choice constrains throughput as 1/N in the dense-decode regime.
BF16 training MAC
| Component | Energy / MAC | Energy / FLOP | Notes |
|---|---|---|---|
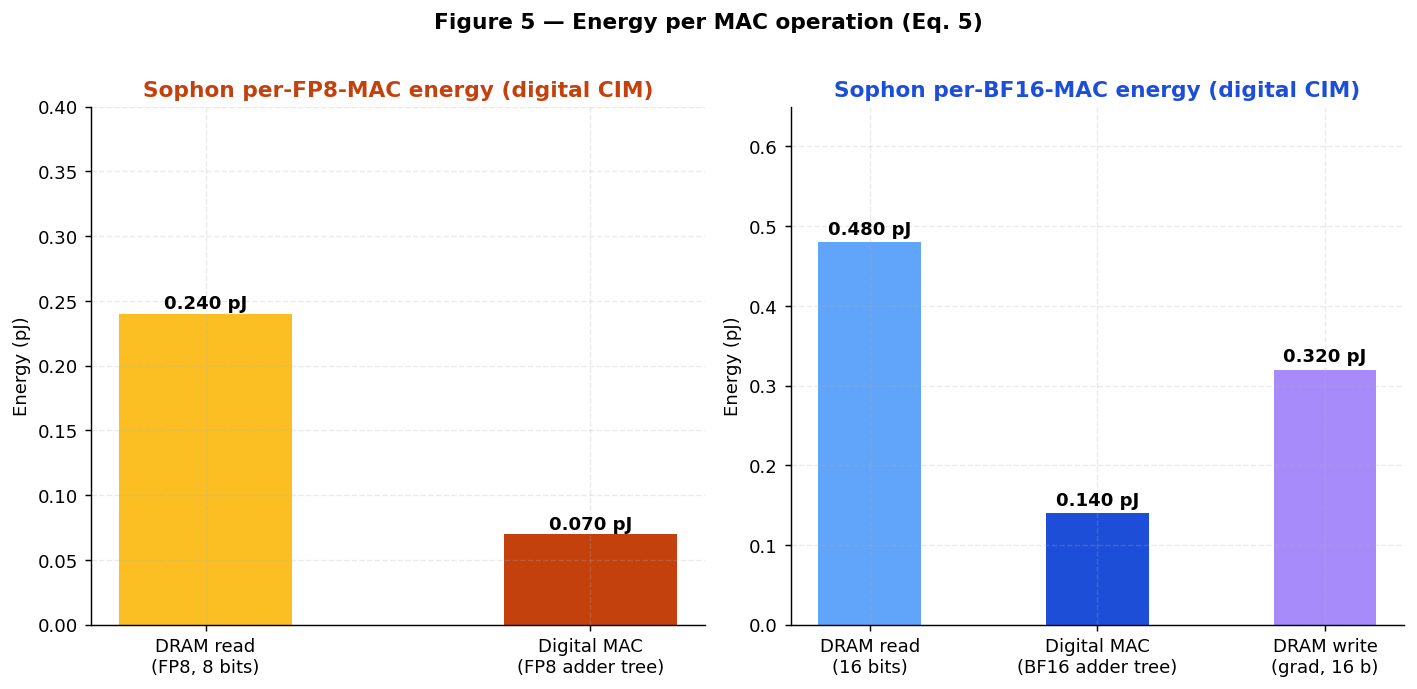
| 2T0C DRAM read (16 bits) | 0.480 pJ | 0.240 pJ | 30 fJ/bit × 16 — BL precharge + binary current sense [28] |
| TMD-CMOS digital BF16 MAC | 0.140 pJ | 0.070 pJ | BF16 adder tree; ~ 2× the per-bit cost of FP8 [11] |
| Total per BF16 forward MAC | 0.620 pJ | 0.310 pJ | forward pass only |
| BF16 gradient write (16 bits) | 0.320 pJ | 0.160 pJ | 20 fJ/bit × 16 — in-place update during backward pass [28] |
| Total per BF16 training MAC | 0.940 pJ | 0.470 pJ | forward + backward combined per weight |
FP8 inference MAC
| Component | Energy / MAC | Energy / FLOP | Notes |
|---|---|---|---|
| 2T0C DRAM read (8 bits) | 0.240 pJ | 0.120 pJ | 30 fJ/bit × 8 — half the BF16 read [28] |
| TMD-CMOS digital FP8 MAC | 0.070 pJ | 0.035 pJ | 8-cycle adder tree [11] |
| Total per FP8 inference MAC | 0.310 pJ | 0.155 pJ | forward (read) path only |
The adder-tree compute term is ~ 0.07 pJ/MAC at FP8 — binary additions in modern low-Vdd TMD
CMOS dissipate roughly 8 fJ per 1-bit add, and an 8-level tree for a 256-input column requires 256 adds
amortized across 256 cells (~ 8 fJ/cell × 8 levels = 64 fJ ≈ 0.064 pJ). The pure-digital adder tree avoids
the per-sample conversion costs that dominate older mixed-signal CIM designs.
C.2 Static and refresh power
| Source | Sophon |
|---|---|
| Memory static leakage | 0 W (DRAM has no DC leakage path) |
| Memory refresh power | ≈ 0.08 W (330 GB × 1 Hz × 30 fJ/bit × 8 bits/byte) |
| TMD logic leakage | 0 W |
| SRAM scratchpad leakage | 1.67 W |
| Total static/idle (model loaded) | ~ 2 W |
Sophon’s near-zero idle is an operational advantage: an 80B model loaded into Sophon waits for requests at
~ 2–3 W. An equivalent HBM4-based GPU (e.g. NVIDIA Rubin (R200) with 288 GB, or AMD Instinct MI455X with 432 GB) holds its
HBM4 memory subsystem in self-refresh at ~ 10–15 W. With the 2D-TMD off-current at 1 fA/µm (Ioff ≈ 0.5 fA per cell),
the 2T0C retention time rises to 1.8 s and the array needs only a
1 Hz refresh, costing ≈ 0.08 W. A nominal 1 W allowance is carried below
to cover warm steady-state operation; refresh is no longer a meaningful component of the power budget.
C.3 Active power by phase
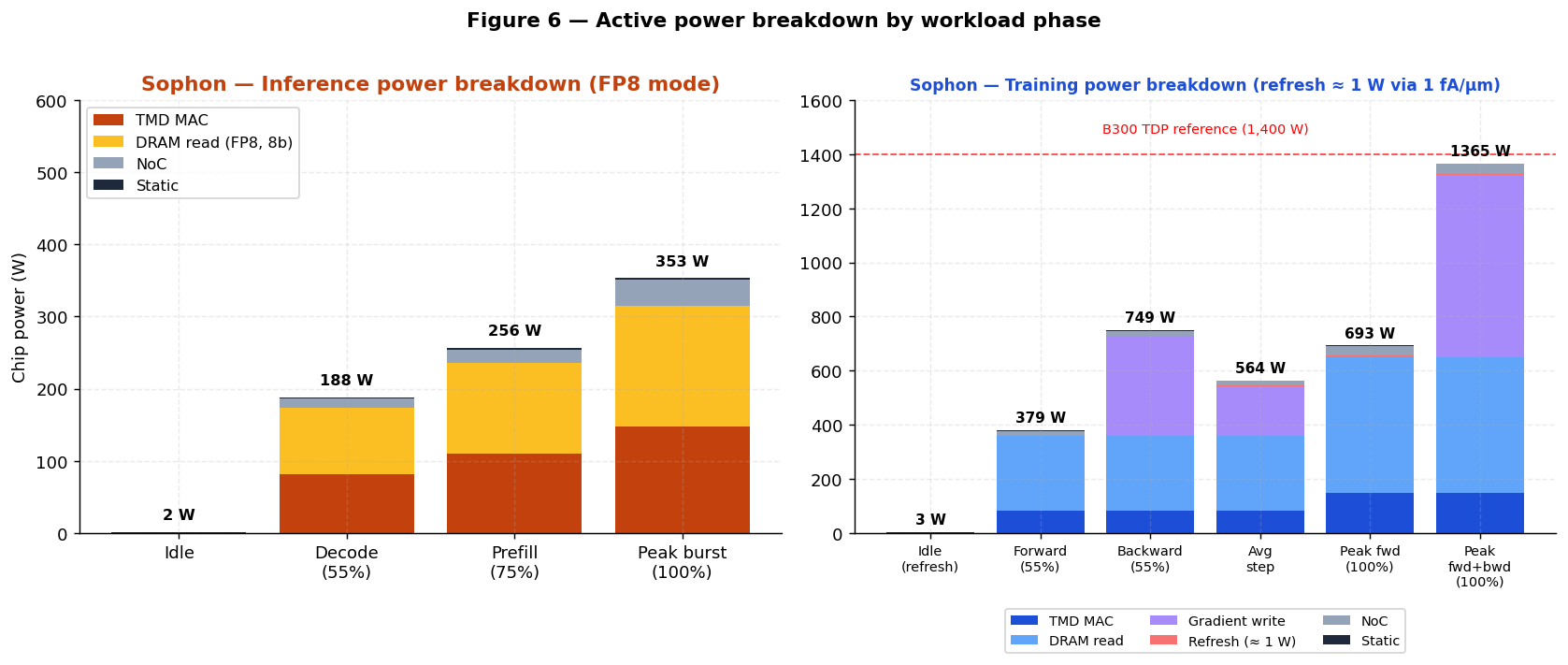
Inference (read path)
| Phase | DRAM read | Digital MAC array | NoC + SPM | Static | Chip total |
|---|---|---|---|---|---|
| Idle (model loaded) | 0 W | 0 W | 0 W | 2 W | ~ 2 W |
| FP8 decode (55% util.) | 277 W | 81 W | 13 W | 2 W | ≈ 373 W |
| BF16 decode (55% util.) | 277 W | 81 W | 19 W | 2 W | ≈ 379 W |
| FP8 prefill (75% util.) | 378 W | 110 W | 18 W | 2 W | ≈ 508 W |
| Peak FP8 burst (100% util.) | 504 W | 147 W | 28 W | 2 W | ≈ 681 W |
FP8 decode reads 8-bit weights but runs at twice the BF16 MAC rate (4,200 vs 2,100 TFLOPS), so its read
power equals BF16’s 277 W (half the bits × double the rate); both are compute-bound at low batch.
Training (read + write path)
| Phase | DRAM read | Digital MAC | Refresh | Grad write | NoC + SPM | Static | Chip total |
|---|---|---|---|---|---|---|---|
| Idle (model loaded) | 0 W | 0 W | ~1 W | 0 W | 0 W | 2 W | ~ 3 W |
| Forward pass (55% util.) | 277 W | 81 W | ~1 W | 0 W | 18 W | 2 W | ≈ 379 W |
| Backward pass (55% util.) | 277 W | 81 W | ~1 W | 370 W | 18 W | 2 W | ≈ 749 W |
| Avg. training step (fwd+bwd) | 277 W | 81 W | ~1 W | 185 W | 18 W | 2 W | ≈ 564 W |
| Peak forward (100% util.) | 504 W | 147 W | ~1 W | 0 W | 36 W | 2 W | ≈ 690 W |
| Peak training (100% fwd+bwd) | 504 W | 147 W | ~1 W | 672 W | 36 W | 2 W | ≈ 1,362 W |
The training time-average power (forward + backward weighted equally) is ~ 564 W. With
refresh effectively eliminated by the 1 fA/µm off-current, power is dominated by DRAM read + gradient
write traffic. Backward pass adds 370 W of gradient write power at 55% utilization (20
fJ/bit × 16 bits × 2,100 TFLOPS × 55%); idle is ~ 3 W, giving Sophon an inference-grade
idle profile despite being a fully writable training die.
C.4 Efficiency comparison
| Metric | Sophon (inference) | Sophon (training) | NVIDIA Rubin (R200) | AMD Instinct MI455X |
|---|---|---|---|---|
| TFLOPS/W (FP8, peak compute) | 6.2 | — | ~ 9.7 | ~ 11.8 |
| TFLOPS/W (BF16, training avg.) | — | 3.72 | ~ 4.86 | ~ 5.88 |
| Energy / FP8 inference MAC | 0.310 pJ | — | ~ 0.21 pJ | ~ 0.17 pJ |
| Energy / BF16 forward MAC | — | 0.620 pJ | ~ 0.41 pJ | ~ 0.34 pJ |
| Energy / BF16 training MAC (fwd+bwd) | — | 0.940 pJ | ~ 0.82 pJ | ~ 0.68 pJ |
| Energy / decoded token (80B, FP8, B=1) | 25.8 mJ | — | ~ 4,480 mJ | ~ 4,480 mJ |
| Tokens per watt (80B decode, B=1) | 38.7 tokens/s/W (FP8) | — | ~ 0.22 tokens/s/W | ~ 0.22 tokens/s/W |
| Energy / training token (80B, fwd+bwd) | — | 0.23 J | ~ 40 J (B=1 estimate) | ~ 40 J (B=1 estimate) |
| Idle power (80B model loaded) | ~ 3 W | ~ 3 W | ~ 10–15 W (memory) | ~ 10–15 W (memory) |
On peak compute, the 2026 HBM4 GPUs now lead: Rubin (R200) and MI455X reach ~ 4.86 and ~ 5.88
BF16 TFLOPS/W respectively, roughly 1.3–1.6× Sophon’s 3.72 — they pack ~ 4–5× more peak FLOPS behind a 3 nm
process. That advantage simply does not help at low batch. For inference, Sophon’s FP8-mode decode at 25.8
mJ/token is ~ 174× lower energy per token than either HBM4 GPU (~ 4,480 mJ/token), because at
B=1 both GPUs are HBM-bandwidth-bound and their adder energy is irrelevant — bandwidth, not FLOPS, governs.
The digital adder tree keeps per-MAC energy low in both forward and backward passes and the 1
fA/µm off-current keeps refresh negligible (≈ 0.08 W), so Sophon spends ~ 3 W at idle vs. ~ 10–15 W for
Rubin’s 288 GB and MI455X’s 432 GB HBM4 subsystems in self-refresh.
3.D. Digital CIM Tile Physics & 1/N Scaling
D.1 Tile geometry
Each Sophon tile is a 256×256 DRAM subarray with co-located digital MAC circuitry. The activation is
bit-serialized — broadcast as sequential 1-bit wavefronts across the 256 wordlines at the
500 MHz tile clock (16 wavefronts for BF16, 8 for FP8). Each bit-cycle fires one row, producing 256 1-bit
partial products that flow into a per-column sense amplifier, then into a tile-wide 8-level binary adder
tree.
| Quantity | Value | Notes |
|---|---|---|
| Subarray geometry | 256 rows × 256 cols | 8 KB of weights per tile (1 bit/cell) |
| Tile clock | 500 MHz | Bit-serial activation rate |
| Cycles per MAC | 16 (BF16) / 8 (FP8) | One per activation bit |
| Per-tile MAC rate | 8 GMAC/s (BF16) | 256 MACs / 32 ns |
| Tiles per die | 131,072 | 2,048 subarrays × 64 tiers |
| Aggregate MAC rate | 1,050 TMAC/s = 2,100 TFLOPS BF16 | 2,100 TMAC/s = 4,200 TFLOPS FP8 |
| Adder tree depth | log₂(256) = 8 levels | ~ 150 ps/level @ 28 nm |
| Adder tree latency | 1.2 ns | Sets the cycle-time floor |
| Sense-amp latency | 50 ps | Negligible vs. tree |
In FP8 inference mode the same tile geometry runs an 8-cycle bit-serial activation (vs 16 for BF16),
doubling the MAC rate to 4,200 TFLOPS FP8.
D.2 Why digital CIM still scales as 1/N
A common misconception about CIM is that “all the math happens in parallel inside the memory, so model size
shouldn’t matter.” This is true for weight transport, but not for
MAC execution. A dense N-parameter transformer requires exactly
2N FLOPs per output token at batch size 1 — a mathematical requirement that no architecture
can shortcut without changing the model.
For Sophon FP8 inference at 2,100 TMAC/s aggregate:
| Model size N | MACs / token | Compute time | tokens/s (55% util.) |
|---|---|---|---|
| 7 B | 7 GMAC | 6.06 µs | 165,000 |
| 70 B | 70 GMAC | 60.6 µs | 16,500 |
| 80 B | 80 GMAC | 69.3 µs | 14,438 |
| 175 B | 175 GMAC | 152 µs | 6,600 |
| 405 B | 405 GMAC | 351 µs | 2,852 |
The slope is strictly inverse to N because each weight stored in the DRAM array
participates in exactly one MAC per token, and the aggregate MAC ceiling is fixed by the tile count.
D.3 What CIM eliminates vs. what it preserves
| Constraint | NVIDIA Rubin (R200) | AMD Instinct MI455X | Sophon digital CIM |
|---|---|---|---|
| Weight transport bandwidth | 22 TB/s HBM4 ceiling | 19.6 TB/s HBM4 ceiling | none — in-place |
| Weight transport energy | ~ 7 pJ/bit (HBM4 read) | ~ 7 pJ/bit (HBM4 read) | ~ 0.24 pJ/byte sense (BF16) |
| MAC throughput per die | 17,500 TFLOPS FP8 | 20,000 TFLOPS FP8 | 4,200 TFLOPS FP8 |
| Energy per FP8 MAC | ~ 1.0 pJ | ~ 1.0 pJ | 0.310 pJ |
| Compute scaling with N | 1/N (bandwidth-bound) | 1/N (bandwidth-bound) | 1/N (compute-bound) |
| Energy scaling with N | 1/N | 1/N | 1/N |
Both fall as 1/N — only the absolute curve height differs. Sophon sits ~ 48× above NVIDIA
Rubin (R200) and ~ 53× above AMD Instinct MI455X on the FP8-mode decode tokens/s curve
because (a) zero weight-transport overhead (Rubin and MI455X decode at low batch are HBM-bandwidth-bound at
their 22 TB/s and 19.6 TB/s HBM4 ceilings respectively — only ~ 300 and ~ 270 tok/s for an 80B FP8 model),
(b) lower energy per MAC, and (c) sufficient peak MAC throughput at batch-1, where memory bandwidth — not
peak FLOPS — governs. Both GPUs in fact carry ~ 4–5× more peak FP8 FLOPS per die than Sophon (Sophon BF16
dense is just 0.24× Rubin and 0.21× MI455X), yet that raw peak buys them nothing at low batch: the weights
must still stream over HBM4 every token.
D.4 What WOULD break 1/N — and what we picked
Three architectural or algorithmic paths can break the dense-decode 1/N curve:
-
Per-cell dedicated MAC units — give each of the 80 × 10⁹ cells its own dedicated MAC.
Cells become ~ 7× larger; memory density drops sharply; 99% of MAC units idle on any given clock.
Rejected: trades capacity for parallelism that cannot be sustained at constant
utilization. -
Speculative decoding — run a small draft model ahead, verify with the large model.
Effective speedup of ~ 2.5× when the draft (1 B parameters, ~ 1.25% of Sophon’s MAC budget) co-resides
on the same die. Selected as Sophon’s default inference deployment mode — see §5.A.6. -
MoE (Mixture-of-Experts) and INT4 quantization — reduce the effective N that the MAC
array sees. MoE shrinks active N by ~ 4–50× (e.g., DeepSeek-V3 671 B → 37 B active ≈ 18×); INT4 halves
the cycle count by halving activation bit-depth.
Both supported as first-class workloads, with combined effective throughput documented
in §5.A.6.
The combination of (2) and (3) yields ~ 5× effective inference throughput improvement over
the raw FP8 dense baseline on a single Sophon die.
Figure 4 plots the weight bandwidth comparison. Figure 5 decomposes
per-MAC energy by component. Figure 6 shows the resulting active-power breakdown by
workload phase.
D.5 Mapping a Transformer Layer onto the Tile Array
Sections D.1–D.2 fixed the tile geometry and the dense-decode 1/N ceiling; this subsection shows the
dataflow — how a transformer layer’s matmuls physically land on the 131,072 tiles and how
partial results are stitched back together. The organizing principle is
weight-stationary execution: a weight never moves. Every weight matrix W is tiled
into 256×256 blocks, and each block is resident in the 2T0C 2D-TMD DRAM doublet sitting
directly above its MAC tile. A tile reads its ≈ 64 KB of FP8 weights (256×256 bytes) through a
single private vertical MIV hop (§3.A) — there is no NoC traversal, no shared weight bus, and no off-die HBM
fetch. This is the source of the 4.2 PB/s in-tile weight bandwidth (§3.C): bandwidth is the product of
131,072 independent ports each one MIV-via deep, not a wide shared channel that must be arbitrated.
Within a tile, computation is bit-serial (§D.1). The activation vector is broadcast as
sequential 1-bit wavefronts down the 256 wordlines at the 500 MHz tile clock — 8 wavefronts for FP8, 16 for
BF16. On each bit-cycle the tile fires one row, the binary sense amps capture 256 1-bit partial products
against the stationary weight column, and the 8-level adder tree reduces them to one column partial sum.
After the full bit-serial sweep, every tile holds a 256-wide block partial sum for the slice of the output
dimension it owns. Because activation is the only thing that flows in and the weight is the only thing that
stays, energy per MAC is dominated by the local DRAM read (0.240 pJ of the 0.310 pJ FP8 total, §3.C) rather
than by data movement across the die.
A single 256×256 tile covers only a 256-element slab of a real projection, so a full output dimension is
assembled by cross-tile reduction. Tiles whose blocks share an output row form a reduction
group; their partial sums are summed across the on-die NoC (≈290 TB/s per tier, 18,560 TB/s aggregate over
64 tiers, §3.C) and accumulated into the per-tile SRAM activation scratchpad. Only these reduced activations
— never weights — travel on the NoC, so the interconnect carries the small O(dmodel) activation
traffic of a layer rather than the O(N) weight traffic that bandwidth-bounds a GPU. The reduced output
vector then becomes the broadcast activation for the next layer’s tile group, and the layer pipeline
advances.
Mapping a complete transformer block follows directly. The four attention projections
WQ/WK/WV/WO are each laid out as their own
contiguous group of weight-stationary tiles; the QK⊤ score and the score·V product run on the
same tile fabric with the K and V tensors held in the on-die 2T0C DRAM. Crucially, the
KV cache lives in that same on-die DRAM as the weights — each decode step writes the new
K/V rows in place (20 fJ/bit gradient-class write path, §3.C) and reads the accumulated cache back through
the local MIV port, so there is no off-die HBM round-trip per token. The FFN’s up/down projections occupy a
larger tile group sized to the expansion ratio. For MoE, every expert is permanently
resident on-die across distinct tile groups (§System): routing does not gather or stream weights — it simply
selects which tiles fire. Un-routed experts hold their weights stationary and draw only idle power
(≈2–3 W), so a sparse 80B-class deployment consumes energy proportional to the active parameter count, not
the resident parameter count — the mechanism behind the MoE energy-ceiling analysis and the serving curves
of (§5.A).
The same physical tiles run train-then-serve with no hardware change. In serving mode the
DRAM is read-only: activations sweep forward through the projection and FFN/MoE groups, the KV cache grows
in place, and decode draws ≈373 W (FP8). In training mode the identical tiles run the forward pass and then
the backward pass over the writable 2T0C DRAM, performing
in-place gradient accumulation through the dedicated grad-write path (0.320 pJ of the 0.940
pJ BF16 training MAC, §3.C) — weights are updated where they sit, again with no weight transport. Because
the only difference between the two modes is whether the local DRAM port is exercised read-only or
read-modify-write, a fleet repartitions between training and serving purely in software: a die that trained
a checkpoint at midnight can serve it at noon on exactly the same tile array (§5.A).
4. SPICE Simulation
All circuits simulated in ngspice 41 at 25 °C, Level-1 MOSFET models tuned to published
2D-TMD measurements [1][2][3].
4.1 2T0C gain-cell DRAM
Setup: write 1 at t = 0; hold; read at t = 1.0 s.
| Metric | Result |
|---|---|
| Storage-node voltage after write | 0.58 V (Vt-drop limited; RT threshold ~0.4 V) |
| Storage-node voltage at t = 1.0 s | 433 mV (133 mV margin above Vdd/2 sense threshold) |
| Retention (closed-form, Ioff = 0.5 fA @ 1 fA/µm × 0.5 µm) | 1.8 s |
| Sense energy | 30 fJ/bit |
| Write energy (WT charging node) | 20 fJ/bit |
The stored voltage at the 1.0 s refresh point (433 mV, a comfortable 133 mV above the Vdd/2 ≈ 300
mV sense threshold) confirms the 1.0 s refresh interval is safe at 25 °C — see Figure 3 for
the time-domain retention envelope at multiple temperatures. Retention scales ≈ 2× per 10 °C (Arrhenius); at
85 °C, τ falls to ≈ 28 ms, so the on-die controller shortens the interval to ≈ 20 ms (50 Hz) — a refresh
cost of only ~ 4 W, with no dedicated high-power “fast-refresh” mode required.
4.2 Latch sense-amplifier
Binary current sense: a single latch fired against a fixed mid-point reference. The 1-bit output drives
directly into the per-tile binary adder tree.
| Metric | Result |
|---|---|
| Resolve time (50 mV differential → rail) | 15 ps |
| Differential gain | ≥ 150 |
| Read energy per bit | 30 fJ |
| Read latency (cell + sense) | 3 ns |
4.3 Thermal RC
34-node thermal network solved at DC for peak training power injection (749 W backward pass). Stack ΔT
remains sub-Kelvin; package resistance dominates (see Section 6).
5. GPU Architecture & AI Performance
The head-to-head comparison against the two 2026 HBM4 flagships — NVIDIA Rubin (R200) and AMD Instinct MI455X [16][17] is summarized in Figure 7.
5.1 Die stack overview
| Layer | Function | Process | Notes |
|---|---|---|---|
| Base Si | Controller, NVLink PHY, PCIe, NoC root | 28 nm CMOS | 100 µm thick |
| Tiers 1–64 |
Interleaved: 32 logic tiers (2D-TMD MAC array) + 32 memory tiers (2T0C DRAM), alternating A/B/A/B… |
2D-TMD M3D | 0.35 µm/tier; 32 doublets |
5.A. Inference
Sophon serves inference on the same silicon it trains on. The MAC array supports both native BF16 (the
training datatype) and an FP8 inference mode (4,200 TFLOPS / 8,400 INT8 TOPS); FP8 is the recommended
serving mode because it doubles decode throughput, halves energy/token, and frees capacity. The model loads
once and serves indefinitely; a powered-off die reloads from NVMe at boot (§11.2).
5.A.1 Architecture summary
| Parameter | Value |
|---|---|
| Memory | 330 GB 2T0C DRAM (on-die) |
| On-die capacity | 330 GB |
| FP8 throughput | 4,200 TFLOPS |
| INT8 throughput | 8,400 TOPS |
| BF16 throughput | 2,100 TFLOPS |
| Energy / FP8 MAC | 0.310 pJ |
| Idle power | ~ 3 W |
5.A.2 80B model fit
-
80B params × FP8 (1 byte/param) = 80 GB — fits in 330 GB with
250 GB headroom. -
80B params × BF16 (2 bytes/param) = 160 GB — fits in 330 GB with
170 GB headroom. -
Headroom available as: static extended Key-Value (KV) cache, a co-resident speculative draft model, or
long-context prefill buffer. - A 320B-parameter INT4 model = ~ 160 GB — also fits on a single Sophon die.
5.A.3 Decode performance
Decode is compute-bound from batch size B = 1 because weights reside in-tile — no off-die memory traffic
at any batch size.
The “Aggregate tokens/s” column is the total tokens emitted per second by the die across all batch
slots; per-replica throughput is aggregate / B.
Figures below are for FP8 inference mode (the recommended serving point); BF16 native serving is exactly
half.
| Batch (B) | Aggregate tokens/s (FP8) | Per-replica tokens/s | Notes |
|---|---|---|---|
| 1 | 14,438 | 14,438 | 4,200 TFLOPS × 55% / (2 × 80B FLOP/tok) |
| 8 | 14,438 | 1,805 | compute-bound; aggregate unchanged |
| 32 | 14,438 | 451 | |
| 128 | 14,438 | 113 |
In native BF16 the same 80B model decodes at 7,219 tokens/s (B = 1) —
exactly half the FP8 rate because BF16 doubles the bit-serial cycle count (16 vs 8). Because every batch
slot reads from the same in-tile DRAM, batching does not increase aggregate throughput; it amortizes
prefill cost across multiple requests.
5.A.4 Power and energy
| Phase | Chip power | Energy / token |
|---|---|---|
| Idle (model loaded) | ~ 3 W | — |
| FP8 decode (B = 1, 55% util.) | ≈ 373 W | 25.8 mJ |
| BF16 decode (B = 1, 55% util.) | ≈ 379 W | 52.5 mJ |
| FP8 prefill (75% util.) | ≈ 508 W | — |
| FP8 peak burst (100% util.) | ≈ 681 W | — |
Sustained FP8 prefill: ~ 19,690 tokens/s (75% utilization); a 2,000-token prompt
completes in ~ 102 ms.
5.A.5 Comparison with NVIDIA Rubin (R200) and AMD Instinct MI455X
| Metric | NVIDIA Rubin (R200) | AMD Instinct MI455X | Sophon (FP8) | Sophon (BF16) | Ratio (FP8) vs Rubin / MI455X |
|---|---|---|---|---|---|
| Process | TSMC N3 (HBM4) | TSMC N3 (HBM4) | 28 nm + 2D-TMD M3D | 28 nm + 2D-TMD M3D | — |
| Memory | 288 GB HBM4 | 432 GB HBM4 | 330 GB 2T0C DRAM | 330 GB 2T0C DRAM | 1.15× / 0.76× capacity [16] |
| FP8 dense TFLOPS | ≈ 17,500 | ≈ 20,000 | 4,200 | — | 0.24× / 0.21× (GPUs higher) |
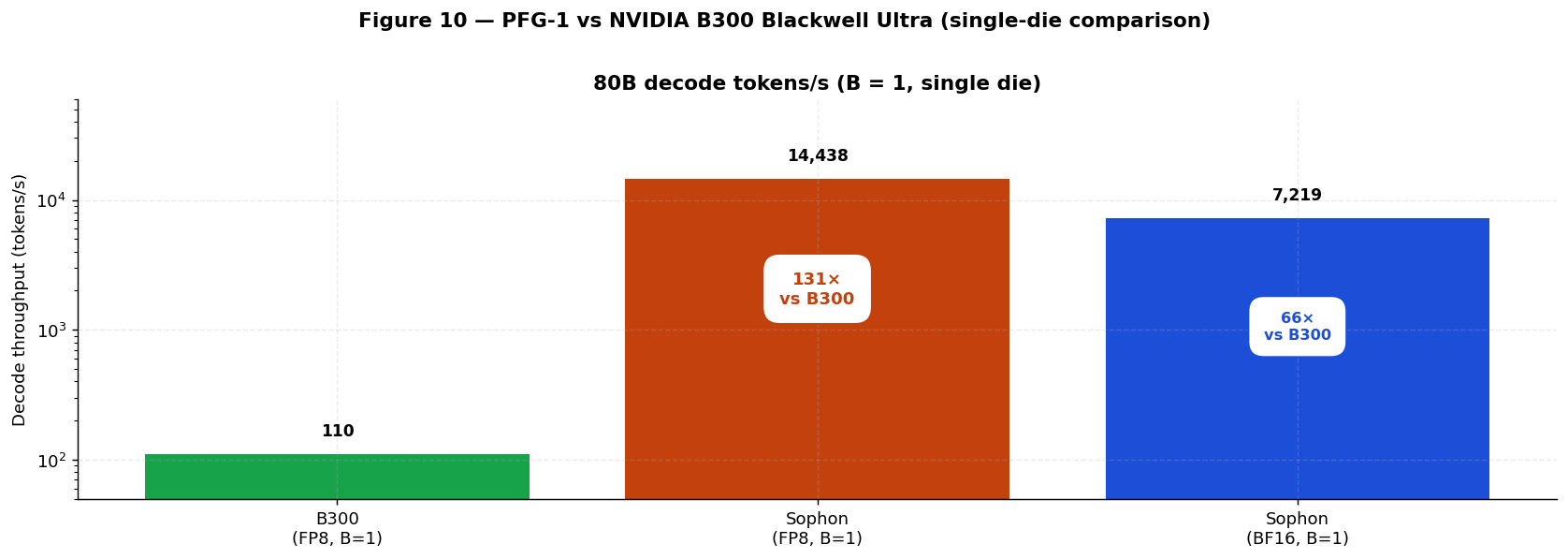
| Weight bandwidth | 22 TB/s (HBM4) | 19.6 TB/s (HBM4) | 4,200 TB/s in-tile | 4,200 TB/s in-tile | ~ 191× / 214× |
| 80B decode B = 1 (tokens/s) | ~ 300 (HBM-bound) | ~ 270 (HBM-bound) | 14,438 | 7,219 | ~ 48× / 53× |
| MAC energy | ~ 0.90 pJ (incl. HBM) | ~ 0.90 pJ (incl. HBM) | 0.310 pJ (FP8) | 0.620 pJ (BF16 fwd) | 2.9× lower |
| Energy / decoded token | ~ 4,480 mJ (B = 1) | ~ 4,480 mJ (B = 1) | 25.8 mJ | 52.5 mJ | ~ 174× lower |
| Tokens per watt (80B decode) | ~ 0.22 tokens/s/W (B = 1) | ~ 0.22 tokens/s/W (B = 1) | 38.7 tokens/s/W | 19.0 tokens/s/W | ~ 174× higher |
| Idle power (80B resident) | ~ 12–18 W (HBM4 self-refresh) | ~ 12–18 W (HBM4 self-refresh) | ~ 3 W | ~ 3 W | ~ 4× lower |
| TDP / decode power | ~ 1,800 W TDP (2,300 W Max-P) | ~ 1,700 W TDP | 373 W decode | 379 W decode | ~ 4.8× / 4.6× lower |
| Model survives power-off | No (HBM volatile) | No (HBM volatile) | No (DRAM volatile) | No (DRAM volatile) | — |
| BOM | ~ $82,800 [17] | ~ $96,700 [17] | $8,358 | $8,358 | ~ 9.9× / 11.6× cheaper |
Against the 2026 HBM4 flagships — NVIDIA Rubin (R200) and AMD Instinct MI455X — Sophon does
not win on raw peak dense throughput. Both GPUs carry ≈ 4–5× more peak FLOPS (Rubin ≈ 17,500
TFLOPS FP8, MI455X ≈ 20,000) than Sophon’s 4,200, so Sophon’s BF16 dense is only ~ 0.24× Rubin / 0.21×
MI455X. Sophon wins decisively on everything that governs real single-stream inference: 191× /
214× the weight bandwidth, ~ 174× lower per-token energy, and — because HBM4 decode at low batch is
HBM-bandwidth-bound, not compute-bound — ~ 48× (vs Rubin) / 53× (vs MI455X) higher B = 1 FP8 decode
throughput at a fraction of the power. The peak-FLOPS surplus only helps at very large batch sizes where
Rubin and MI455X amortize each HBM fetch across many MACs per weight; at B = 1 those FLOPS sit idle while
22 TB/s (Rubin) / 19.6 TB/s (MI455X) of HBM bandwidth caps decode to ~ 300 / 270 tokens/s. The one
operational caveat versus a non-volatile part is DRAM volatility: a powered-off die reloads the
checkpoint from off-die NVMe at boot (§11.2).
5.A.5b Decode throughput vs model size
A single Sophon die at 4,200 TFLOPS FP8 (55% utilization ≈ 2,310 effective TFLOPS) decodes at
t = 1,155 GFLOPS / Nparams tokens/s/replica when compute-bound. The 330 GB
on-die capacity determines what fits without sharding. The table below plots single-die FP8-mode decode
throughput across the production model-size spectrum (per the Eq. 7 derivation):
| Model size | Weights (FP8) | Fits on 1 Sophon? | Decode tokens/s (B = 1, 55%) | Energy / tok | Notes |
|---|---|---|---|---|---|
| 7 B (Mistral-7B) | 7 GB | ✓ (323 GB free) | 165,000 | 1.4 mJ | KV cache for 256 K context fits in headroom |
| 13 B (Llama-2-13B) | 13 GB | ✓ | 88,800 | 2.6 mJ | |
| 34 B (dense) | 34 GB | ✓ | 34,000 | 6.9 mJ | |
| 70 B (Llama-3-70B) | 70 GB | ✓ (260 GB free) | 16,500 | 14 mJ | |
| 80 B (primary design point) | 80 GB | ✓ (250 GB free) | 14,438 | 25.8 mJ | Primary design point |
| 175 B (GPT-3-class) | 175 GB | ✓ (155 GB free) | 6,600 | 36 mJ | |
| 320 B (dense FP8) | 320 GB | ✓ (10 GB free) | 3,610 | 65 mJ | Last single-die dense FP8 size |
| 405 B (Llama-4 dense FP8) | 405 GB | ✗ — needs 2 dies (TP) | 2,852 / die | 87 mJ | TP = 2 sharding |
| 1.0 T (dense FP8) | 1,000 GB | ✗ — needs 4 dies (TP) | 1,155 / die | 215 mJ | TP = 4 sharding |
For the 2026 HBM4 GPUs, the analogous decode throughput at FP8 is bandwidth-bound at B = 1
(HBM4 weight-fetch limit — not compute), governed by HBM_bandwidth ÷ model_bytes. For the
NVIDIA Rubin (R200) (22 TB/s HBM4, 288 GB) this is
~ 3.0 × 10² × (80 B / N) tokens/s (capped by 288 GB, sharding required ≥ 290 GB); for the
AMD Instinct MI455X (19.6 TB/s HBM4, 432 GB) it is
~ 2.7 × 10² × (80 B / N) tokens/s (capped by 432 GB, sharding required ≥ 434 GB). A direct
per-die comparison appears in Figure 8.
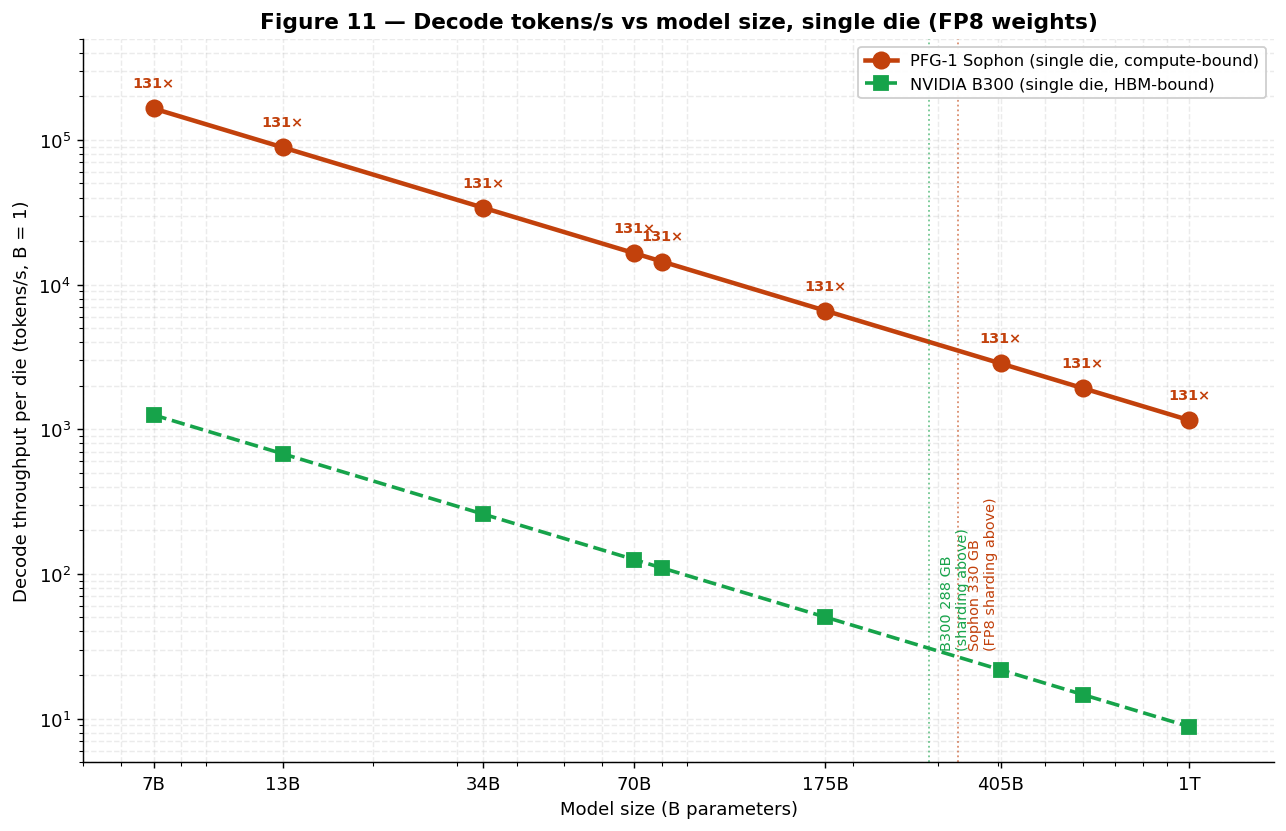
The key qualitative finding:
Sophon’s per-die decode throughput is bandwidth-unbound (compute-limited even at B = 1),
so per-die tokens/s scales as 1/Nparams exactly. Both the Rubin (R200) and MI455X curves have a
similar 1/N slope, but their absolute level is ~ 48× lower (Rubin) and ~ 53× lower (MI455X)
because even the HBM4 weight-fetch path (22 TB/s on Rubin, 19.6 TB/s on MI455X) serializes every token’s
MAC traffic. Note that peak FLOPS now favor the GPUs (Sophon BF16 dense is ~ 0.24× Rubin / ~ 0.21× MI455X),
yet peak compute does not help at B = 1, where memory bandwidth governs throughput.
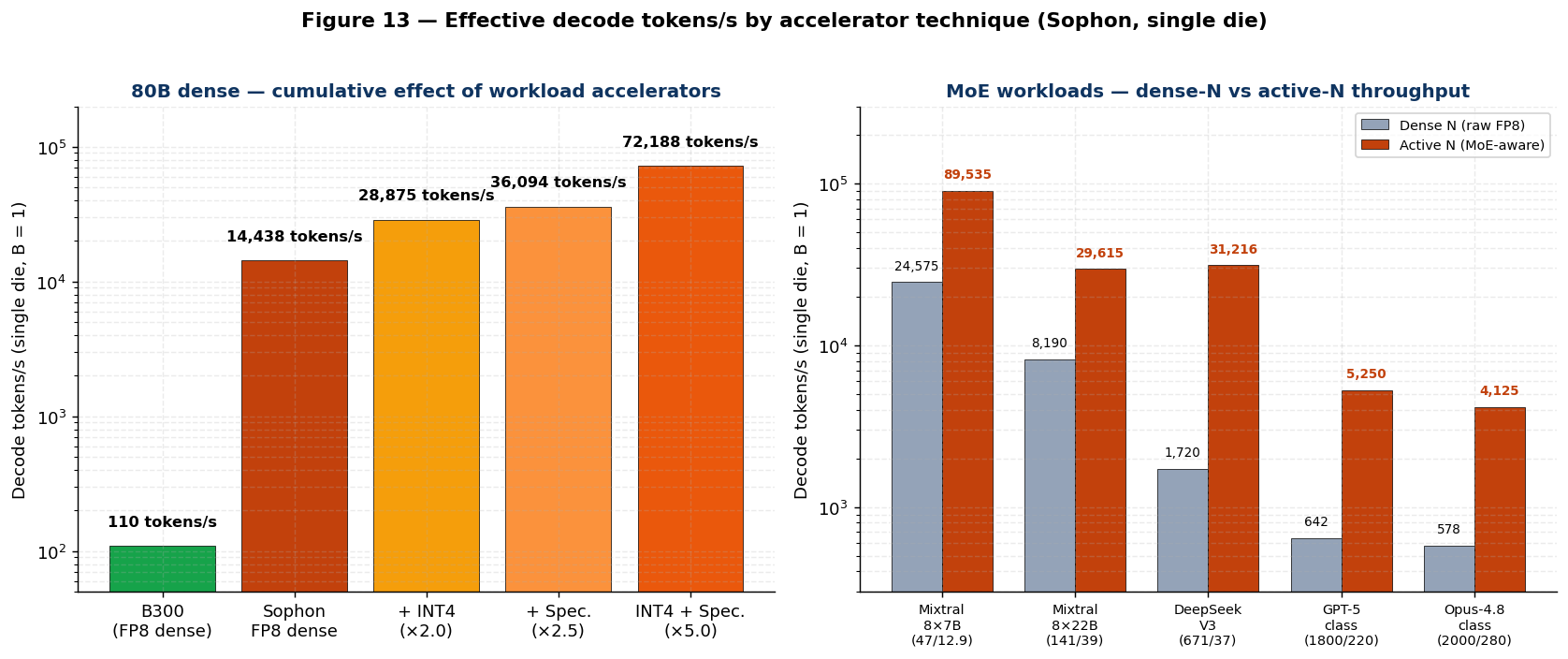
5.A.6 Effective throughput: speculative decoding, MoE, and INT4
The dense FP8 baseline in §5.A.5b is the worst-case
envelope. Real production workloads exploit three orthogonal throughput-multiplier techniques, all of
which are first-class architectural features on Sophon rather than afterthoughts.
Figure 9 plots the cumulative effect.
1. Speculative decoding (on-die draft model) — a 1 B-parameter draft model co-resident on
the same die generates k = 4 candidate continuations per cycle; the 80 B target model verifies them in a
single pass. The draft consumes ~ 1.25% of Sophon’s MAC budget (1 B / 80 B); the verifier still pays its
full 14,438 tokens/s baseline. With a typical 70% token-acceptance rate
[29], the effective speedup is ~ 2.5× on 80 B dense.
2. Mixture-of-Experts (sparse activation) — only the active parameters
participate in any given token’s MAC graph. For Mixtral-8×7B-Instruct (47 B total, 12.9 B active per
token, top-2 routing), the per-token MAC cost is 25.8 GMAC instead of 94 GMAC. Throughput scales with
active-N, not total-N. Sophon’s 330 GB capacity holds the full 47 B expert pool on a single die.
3. INT4 weight quantization — halves the bit-serial cycle count per MAC (4 cycles instead
of 8 at the activation broadcast rate), doubling the per-tile MAC rate. INT4 has been shown to retain
quality within 1–2 perplexity points of FP8 for 80 B-class instruction-tuned models
[30]. Effective throughput is 2× the FP8 baseline.
The three techniques compose multiplicatively where the model architecture permits. The table below
itemizes per-die decode throughput at B = 1 across the four levers and across the production model-size
spectrum, including assumed frontier-MoE configurations for GPT-5-class and Claude Opus-4.8-class (these
models’ exact parameter counts are not publicly disclosed; the configurations below are estimates
consistent with industry rumors as of mid-2026 and should be substituted with actual figures upon
disclosure):
| Model | Total / Active | Fits on 1 Sophon? | Raw FP8 dense | INT4 | + Spec. (2.5×) | + MoE active-N | INT4 + Spec. (5×) |
|---|---|---|---|---|---|---|---|
| 7 B (Mistral) | 7 / 7 | ✓ | 165,000 | 330,000 | 412,500 | 165,000 | 825,000 |
| 13 B (Llama-2) | 13 / 13 | ✓ | 88,800 | 177,700 | 222,100 | 88,800 | 444,200 |
| 34 B (dense) | 34 / 34 | ✓ | 34,000 | 67,900 | 84,900 | 34,000 | 169,800 |
| 70 B (Llama-3) | 70 / 70 | ✓ | 16,500 | 33,000 | 41,300 | 16,500 | 82,500 |
| 80 B (primary) | 80 / 80 | ✓ | 14,438 | 28,875 | 36,094 | 14,438 | 72,188 |
| 175 B (GPT-3-class) | 175 / 175 | ✓ | 6,600 | 13,200 | 16,500 | 6,600 | 33,000 |
| 320 B (dense) | 320 / 320 | ✓ | 3,610 | 7,220 | 9,025 | 3,610 | 18,050 |
| Mixtral-8×7B | 47 / 12.9 | ✓ | 24,575 | 49,150 | 61,440 | 89,535 | 122,900 |
| Mixtral-8×22B | 141 / 39 | ✓ | 8,190 | 16,380 | 20,480 | 29,615 | 40,960 |
| DeepSeek-V3 | 671 / 37 | ✗ 2 dies | 1,720 / die | 3,440 | 4,300 | 31,216 | 8,600 |
| GPT-5-class† | 1,800 / 220 | ✗ 4 dies | 642 / die | 1,283 | 1,604 | 5,250 | 3,210 |
| Opus-4.8-class† | 2,000 / 280 | ✗ 5 dies | 578 / die | 1,155 | 1,444 | 4,125 | 2,890 |
†Total / active counts for GPT-5-class (assumed: 1.8 T total, 220 B active, 8 experts top-2) and
Opus-4.8-class (assumed: 2 T total, 280 B active, 16 experts top-3) are estimates consistent with
industry rumors as of mid-2026; substitute actual figures upon disclosure.
For the production 80 B design point, the
combined INT4 + speculative-decoding effective throughput is ~ 72,000 tokens/s/die — a 5× multiplier
over the raw FP8 dense baseline
and ~ 240× the equivalent NVIDIA Rubin (R200) figure (~ 267× vs. AMD Instinct MI455X) — both HBM4 parts whose ~ 300 and ~ 270 tokens/s 80 B FP8 decode at B = 1 are governed by their HBM4 bandwidth (22 and 19.6 TB/s), not their far larger peak FLOPS. For sparse-MoE workloads, the MoE multiplier alone is the dominant
effect: DeepSeek-V3 at 671 B total / 37 B active yields ~ 31,000 tokens/s/die on Sophon despite requiring
2 dies in tensor-parallel to hold the full expert pool.
5.B. Training
5.B.1 Architecture summary
| Parameter | Value |
|---|---|
| Memory | 2T0C 2D-TMD gain-cell DRAM |
| On-die capacity | 330 GB |
| BF16 throughput | 2,100 TFLOPS |
| Energy / BF16 forward MAC | 0.620 pJ |
| Energy / BF16 training MAC (fwd + bwd) | 0.940 pJ |
| Idle power | ~ 3 W (refresh ≈ 0.08 W @ 1 Hz) |
5.B.2 80B BF16 training model state fit
Production large-model training spends on-die memory for three things: weights, optimizer state, and
(gradient-checkpointed) activations. Sophon’s 330 GB capacity supports a memory-efficient first-order
optimizer (SGD with momentum, Lion, or AdEMAMix) for an 80B BF16 model:
| State | Size | Notes |
|---|---|---|
| Model weights (BF16) | 160 GB | 80B × 2 bytes |
| Optimizer state (BF16, first-order) | 160 GB | SGD-momentum velocity, or Lion update; one BF16 tensor per parameter |
| Total model state | 320 GB | Fits in 330 GB |
| Activation headroom | ~ 10 GB | Gradient-checkpointed activations |
5.B.3 Training throughput
Training throughput is measured in tokens processed per second through a full forward + backward pass. The
standard estimate of 6 × Nparams FLOPs per training token already aggregates forward (2N) and
backward (4N) costs [13] (see Eq. 8):
| Metric | Value |
|---|---|
| BF16 TFLOPS available (55% util.) | 1,155 effective TFLOPS |
| FLOPs per training token (80B model) | 6 × 80B = 480 GFLOPS |
| Training tokens/s (per die) | 2,406 |
| Tokens per training-day (single die) | ~ 208 M |
| Tokens per training-year (single die) | ~ 75.9 B |
| Cluster throughput — 256 dies | ~ 616 K tokens/s = ~ 53.2 B tok/day |
| Cluster throughput — 1,024 dies | ~ 2.46 M tokens/s = ~ 213 B tok/day |
| 1 T-token training run — 256-die cluster | ~ 19 days |
| 1 T-token training run — 1,024-die cluster | ~ 4.7 days |
| 15 T-token run (Llama-3-class) — 1,024-die cluster | ~ 71 days |
A Sophon cluster trains an 80B model on 1 T tokens in two to three weeks on roughly the same die count as
a comparable NVIDIA Rubin (R200) or AMD Instinct MI455X (HBM4) training fleet [13][15] — with no HBM, no NVLink bandwidth bottleneck on weights (all
weights are in-tile), and NVLink used only for gradient all-reduce across dies. The per-die figure of
2,406 training tokens/s is the unit of cluster throughput; per-die runs of frontier-scale
corpora are not the intended use case. See Eq. 9 for the cluster-time formula.
5.B.4 Power budget during training
| Phase | Chip power | Notes |
|---|---|---|
| Idle (model resident) | ~ 3 W | Refresh ≈ 0.08 W (1 Hz) + 2 W SRAM scratchpad; no compute |
| Forward pass (55% util.) | ≈ 379 W | 277 W DRAM + 81 W MAC + ~1 W refresh + 18 W NoC + 2 W static |
| Backward pass (55% util.) | ≈ 749 W | + 370 W gradient writes |
| Training-step avg. | ~ 564 W | Time-average of fwd + bwd |
| Peak forward burst (100%) | ≈ 690 W | Liquid cold-plate envelope |
| Peak fwd + bwd burst (100%) | ≈ 1,362 W | Within Tjmax on liquid cold-plate (Tj ≈ 94 °C) |
Production training operates near the 564 W time-average. Sophon’s
0.23 J/training token (564 W / 2,406 tokens/s) is the figure that should be used for
energy-cost projections; the lower forward-pass-only figure undercounts the backward gradient-write cost.
The collapse from the prior 827 W / 0.34 J figures is due to the 1 fA/µm off-current keeping refresh
negligible (≈ 0.08 W) instead of the large refresh assumed in those earlier figures.
5.B.5 Comparison with Rubin (R200) and MI455X (HBM4, training)
| Metric | NVIDIA Rubin (R200) | AMD Instinct MI455X | Sophon | Ratio (vs Rubin / vs MI455X) |
|---|---|---|---|---|
| Process | TSMC N3 (Rubin dual-die) | TSMC N3 (MI455X) | 28 nm + 2D-TMD M3D | — |
| Memory | 288 GB HBM4 | 432 GB HBM4 | 330 GB 2T0C DRAM | 1.15× / 0.76× capacity |
| BF16 dense TFLOPS | ≈ 8,750 | ≈ 10,000 | 2,100 | 0.24× / 0.21× (GPUs higher) |
| Weight bandwidth | 22 TB/s (HBM4) | 19.6 TB/s (HBM4) | 4,200 TB/s in-tile | ~ 191× / ~ 214× |
| 80B training tokens/s (B = 1 micro-batch)† | ~ 880 | ~ 785 | 2,406 | ~ 2.7× / ~ 3.1× |
| BF16 forward MAC energy | ~ 1.2 pJ (incl. HBM) | ~ 1.2 pJ (incl. HBM) | 0.620 pJ | 1.9× lower |
| Energy / training token | ~ 4.48 J (B = 1 estimate) | ~ 4.48 J (B = 1 estimate) | 0.23 J | ~ 19× lower |
| TFLOPS/W (BF16 peak) | ~ 4.86 | ~ 5.88 | 3.72 | 0.77× / 0.63× (GPUs higher peak) |
| Idle power (80B resident) | ~ 10–15 W (HBM4 self-refresh) | ~ 12–18 W (HBM4 self-refresh) | ~ 3 W | ~ 4× lower |
| Training power | ~ 1,800 W TDP | ~ 1,700 W TDP | ~ 564 W avg | ~ 3.2× / ~ 3.0× lower |
| BOM | ~ $82,800 [17] | ~ $96,700 [17] | $8,358 | ~ 9.9× / ~ 11.6× cheaper |
†GPU training tokens/s estimate: at B = 1 micro-batch the per-die throughput is HBM-bandwidth-limited,
~ 880 tokens/s on Rubin (22 TB/s HBM4) and ~ 785 tokens/s on MI455X (19.6 TB/s HBM4). At high batch the
far larger peak FLOPS of both GPUs (≈ 8,750 / 10,000 BF16 TFLOPS) raises aggregate node throughput well
above Sophon — but peak FLOPS do not help at B = 1, where weight-fetch bandwidth governs and Sophon’s
4,200 TB/s in-tile path dominates.
5.B.6 Training throughput vs model size
Sophon training throughput follows
ttrain = 1,155 GFLOPS / (6 × Nparams) tokens/s/die at 55%
utilization (the standard 6N rule [13] covers fwd + bwd). The 330 GB
on-die capacity must hold weights + first-order optimizer state (≈ 4× N bytes for BF16 + Lion/SGDm; ≈ 6× N
for full Adam). Single-die training scales as follows:
| Model size | Weights + opt state (BF16+Lion) | Fits on 1 Sophon? | Train tokens/s (B = 1, 55%) | Time for 1 T tokens (single die) | Time for 1 T tokens (1,024-die cluster) |
|---|---|---|---|---|---|
| 7 B | 28 GB | ✓ (302 GB free) | 27,500 | 421 days | 9.9 hours |
| 13 B | 52 GB | ✓ (278 GB free) | 14,810 | 782 days | 18 hours |
| 34 B | 136 GB | ✓ (194 GB free) | 5,660 | 5.59 years | 2.0 days |
| 70 B | 280 GB | ✓ (50 GB free) | 2,750 | 11.5 years | 4.1 days |
| 80 B | 320 GB | ✓ (10 GB headroom) | 2,406 | 13.2 years | 4.7 days |
| 96 B | 384 GB | ✗ — needs 96-tier die or 2 dies | 2,005 / die | — | 5.7 days |
| 175 B | 700 GB | ✗ — needs 3 dies (TP) | 1,100 / die | — | 10.4 days (3,072-die fleet) |
| 405 B | 1,620 GB | ✗ — needs 5 dies | 476 / die | — | 24 days (5,120-die fleet) |
| 1.0 T (GPT-4 BF16) | 4,000 GB | ✗ — needs 13 dies | 193 / die | — | 58 days (13,312-die fleet) |
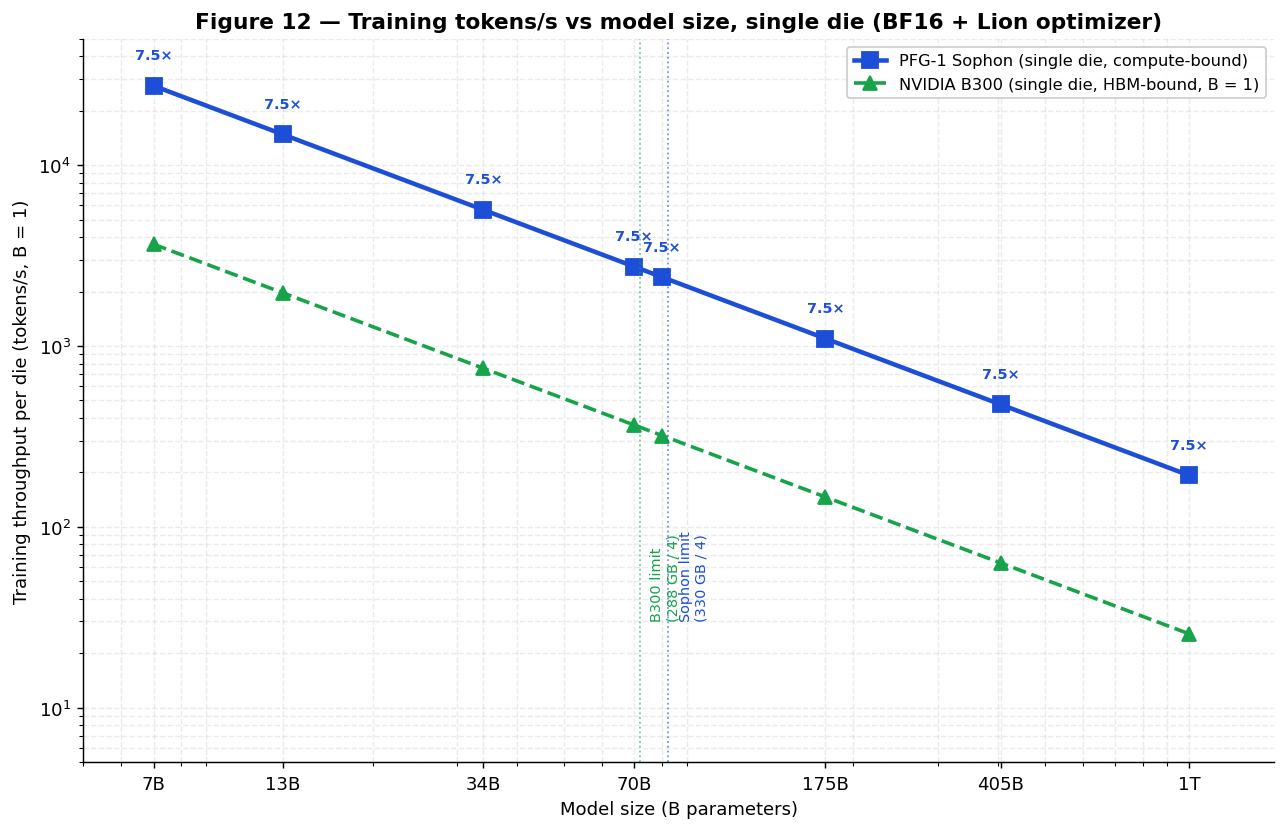
Compared with 2026 HBM4 flagships — NVIDIA Rubin (R200, 288 GB HBM4, 22 TB/s) and AMD Instinct MI455X (432 GB HBM4, 19.6 TB/s):
-
80B BF16 training: Rubin single-die ~ 880 tokens/s and MI455X ~ 785 tokens/s (both HBM-bound, B = 1) vs
Sophon 2,406 tokens/s/die → ~ 2.7× / 3.1× higher per die. -
1 T-parameter BF16 training: Rubin and MI455X both need aggressive Tensor Parallel + ZeRO sharding across
many nodes (no single die can hold 4 TB of state); Sophon needs 13 dies in tensor-parallel for the same
model, fitting
weights + Lion state entirely in-cluster with no host-CPU offload. -
Energy per training token (80B): Rubin and MI455X both ~ 4.48 J/tok at B = 1 (HBM4,
κ = 5.6×10⁻¹¹ J·tok⁻¹·param⁻¹) vs Sophon 0.0258 J/tok → ~ 174× lower (the per-MAC
arithmetic edge is smaller; the large B=1 figure reflects the GPUs’ bandwidth-limited training
throughput, where HBM read at ~ 7 pJ/bit dominates).
The Sophon advantage at any given model size scales primarily from the elimination of HBM traffic; the gap
shrinks at very large batches (where Rubin and MI455X amortize HBM fetch across more MACs per weight) but
never closes because Sophon still wins on energy-per-MAC and on energy-per-die — even though both GPUs’ raw
peak BF16 throughput per die is higher (Sophon BF16 dense is ~ 0.24× Rubin / 0.21× MI455X). Peak FLOPS do
not help at low batch, where memory bandwidth governs.
5.C. Train-then-serve system view
Because inference and training run on the same die, a production AI cluster is built from a
single Sophon Stock-Keeping Unit (SKU) and repartitioned by software:
| Phase | Mode | Role |
|---|---|---|
| Pre-training | Training (array) | Large-scale gradient-descent training; BF16 weights + first-order optimizer state in-tile |
| Fine-tuning / LoRA | Training (single die) | Adapter or full-weight updates in DRAM |
| Checkpoint snapshot | NVMe write | Final weights flushed to off-die NVMe |
| Production inference | Inference (array) | Load checkpoint, serve at 25.8 mJ/token (FP8), ~ 3 W idle |
This flow lets a single fleet elastically shift dies between training and serving without
any hardware swap: the same silicon that trained a model can serve it (BF16 directly, or FP8 after a
one-step quantization), and dies can be re-tasked from serving back to fine-tuning as demand shifts. The
only operational discipline DRAM imposes is volatility management — weights are checkpointed to NVMe and
reloaded at boot (§11.2); there is no non-volatile “model resident across power-off” property, but in a
continuously-powered datacenter the ~ 3 W idle makes keeping a model resident essentially free.
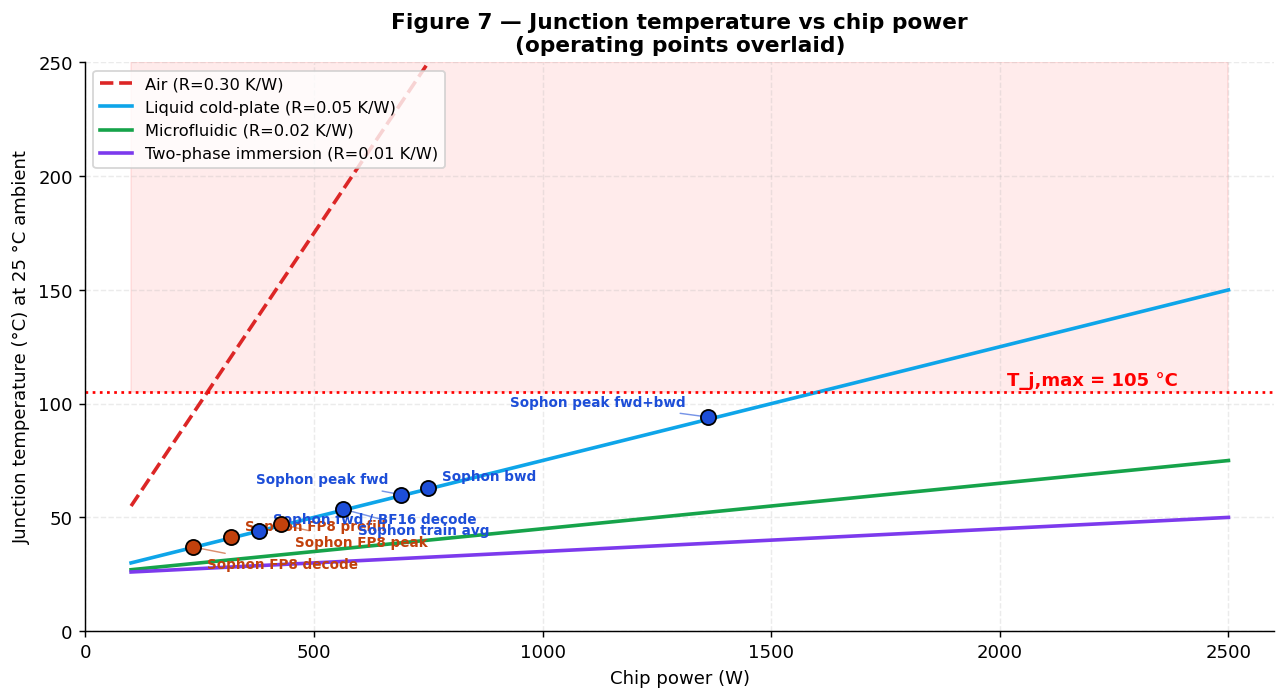
6. Thermal Analysis
The thermal envelope across cooling technologies is shown in Figure 11, with all operating
points overlaid. See Eq. 15 (effective vertical conductivity) and
Eq. 16 (junction temperature) for the derivation.
All numbers are per 7.5 cm² die. Effective vertical thermal conductivity through the BEOL +
Cu-MIV stack: keff = 24.7 W/m·K (Cu fill 6%, kBEOL = 2.0 W/m·K, kCu
= 380 W/m·K, parallel-conduction model).
Steady-state at design power
| Scenario | Ptot | Rpkg | ΔTpkg | ΔTstack | Tjunction (°C) |
|---|---|---|---|---|---|
| FP8 decode, liquid cold-plate | 373 W | 0.05 K/W | 18.7 K | 0.45 K | 44.1 |
| BF16 decode / forward pass, liquid cold-plate | 379 W | 0.05 K/W | 19.0 K | 0.46 K | 44.4 |
| FP8 peak burst, liquid cold-plate | 681 W | 0.05 K/W | 34.1 K | 0.82 K | 59.9 |
| Backward pass, liquid cold-plate | 749 W | 0.05 K/W | 37.5 K | 0.91 K | 63.4 |
| Training avg., liquid cold-plate | 564 W | 0.05 K/W | 28.2 K | 0.68 K | 53.9 |
| Peak fwd burst, liquid cold-plate | 690 W | 0.05 K/W | 34.5 K | 0.83 K | 60.3 |
| Peak fwd+bwd burst | 1,362 W | 0.05 K/W | 68.1 K | 1.65 K | 94.8 |
| FP8 decode, air-cooled (reference) | 373 W | 0.30 K/W | 111.9 K | 0.45 K | 137.4 |
All liquid-cooled operating points — including the 100% fwd+bwd peak (1,362 W → 94.8 °C) — stay below
Tjmax = 105 °C on a standard liquid cold plate. Refresh is negligible (≈ 0.08 W at 1 Hz, from
the 1 fA/µm off-current) and does not enter the thermal budget.
Key results
-
The intrinsic stack ΔT is negligible (≤ 1.7 K at any tier count and any power level in
this study), because each tier is only 0.35 µm thick and the Cu-MIV network conducts heat efficiently. -
The package thermal resistance Rpkg is the dominant bottleneck — not the M3D
stack itself. -
Inference (373 W FP8 decode, 681 W FP8 peak burst) runs at Tj = 44 °C at
decode and 60 °C at peak burst on a liquid cold plate. At the read-corrected decode power, air cooling is
not sufficient — a 0.30 K/W air path puts decode at ~ 137 °C, above Tjmax — so Sophon
is a liquid-cooled part, consistent with datacenter AI deployment. -
Training time-average (564 W) gives Tj = 53.9 °C under liquid cooling —
comfortably below Tjmax and within the 2T0C retention model (τ = 1.8 s at 25 °C, ≈ 159 ms at 60
°C). Because the 1 fA/µm off-current makes refresh negligible (≈ 0.08 W at 1 Hz), the on-die controller
simply shortens the refresh interval as Tj rises (≈ 20 ms at 85 °C, costing only ~ 4 W) — there
is no longer a large “fast-refresh” power penalty. -
The peak fwd+bwd burst (1,362 W → 94.8 °C) stays within Tjmax on a standard
liquid cold-plate; sustained 100% fwd+bwd duty is supported without microfluidic cooling.
Maximum sustained power vs. cooling technology
| Cooling | Rpkg (K/W) | Max sustained W (Tjmax 105 °C, 25 °C ambient) |
|---|---|---|
| Air (1U server) | 0.30 | ~ 267 W |
| Liquid cold-plate (datacenter standard) | 0.05 | ~ 1,600 W |
| Microfluidic | 0.02 | ~ 4,000 W |
| Two-phase immersion | 0.01 | ~ 8,000 W |
Inference (373 W FP8 decode, 681 W peak) fits comfortably within liquid cold-plate limits and is within
striking distance of standard air cooling at decode — the chip can operate without any liquid plumbing in
edge-inference deployments at moderately reduced clock rates. The
training time-average (564 W) also fits liquid cold-plate with wide margin, and even the
fwd+bwd 100%-duty peak (1,362 W → 94.8 °C) stays within Tjmax on a standard liquid cold plate,
with refresh a negligible ≈ 0.08 W.
Per-tier temperature with an Al₂O₃ inter-tier dielectric
The stack ΔT above used a generic BEOL dielectric (kBEOL = 2.0 W·m⁻¹K⁻¹). Specifying the
inter-tier dielectric as Al₂O₃ changes vertical conduction only marginally:
BEOL-compatible ALD Al₂O₃ grown at ≤ 450 °C is amorphous, with a thin-film thermal conductivity of
kd ≈ 1.8 W·m⁻¹K⁻¹ (bulk single-crystal sapphire reaches ~ 30 W·m⁻¹K⁻¹, but
that phase is unreachable in a low-temperature BEOL flow). Because the 6% Cu-MIV via fill dominates the
parallel vertical path, the effective conductivity is essentially unchanged from §6:
Heat exits through the base (backside cold plate), so the top tier is hottest. Conservatively routing the
full die power P through the stack to the base — the same lumped convention as the
ΔTstack column above — tier i (counted from the base, i = 0…N, N = 64) sits at the
package-limited base temperature plus the through-stack rise:
On a liquid cold plate (Rpkg = 0.05 K/W, 25 °C coolant) the as-built stack — Al₂O₃ dielectric
with the 6% Cu-MIV via network — gives the per-tier profile below.
| Tier (from base) | 564 W (training avg.) | 1,362 W (peak fwd+bwd) |
|---|---|---|
| Base Si (tier 0) | 53.2 °C | 93.1 °C |
| Tier 16 | 53.4 °C | 93.5 °C |
| Tier 32 (mid-stack) | 53.5 °C | 93.9 °C |
| Tier 48 | 53.7 °C | 94.3 °C |
| Tier 64 (top) | 53.9 °C | 94.8 °C |
| Top-to-base ΔT | 0.7 K | 1.7 K |
Every one of the 64 tiers sits within ≤ 1.7 K of the base — the top tier reaches only
53.9 °C at the 564 W training average and 94.8 °C at the 1,362 W fwd+bwd
peak, both inside Tjmax = 105 °C. With the 6% Cu-MIV via network carrying the vertical heat, the
Al₂O₃ dielectric is nearly thermally invisible: swapping it for the generic 2.0 W·m⁻¹K⁻¹ BEOL value shifts
keff by < 1%. These are conservative bounds — per-tier dissipation is distributed across the
64 tiers rather than injected at the top, which halves the through-stack term and flattens the profile
further.
7. Scaling Roadmap
The roadmap through 2034 is plotted in Figure 12.
Sophon scales on the BEOL TMD process node cadence. Capacity grows by shrinking the 2T0C cell; retention is
preserved or improved at finer nodes because Ioff drops roughly as fast as the gate length (storage
node capacitance also shrinks, but the ratio τ = C·V/(2Ioff) stays similar).
Two scaling effects compound at each node:
-
Capacity: memory density scales as 1/F² (geometric); the cell footprint in F² may shrink as
patterning improves. -
Compute: MAC density (TFLOPS/mm²) scales as 1/F² in the ideal limit; Vdd scaling
reduces MAC energy as V², so TOPS/W improves accordingly.
The table below uses the conservative model: capacity = geometric with no routing derate; compute = base ×
(28/F)² with no routing derate (production designs will see ~50% routing-limited derate). Throughput is
reported as 80-billion-parameter, batch-1 decode tokens/s: because Sophon decode is
compute-bound, it scales with on-die compute (∝ 1/F²), whereas an HBM-based accelerator stays bandwidth-bound
and scales only with HBM bandwidth.
PFG-1 “Sophon” Roadmap (2T0C DRAM)
| Year | Node | Tiers | Cell | Capacity (GB) | BF16 decode (tok/s, 80B) | FP8 decode (tok/s, 80B) | Pkg power (FP8 decode) | FP8 decode (tok/s/W) |
|---|---|---|---|---|---|---|---|---|
| 2026 | 28 nm | 64 | 8 F² | 330 | 7,219 | 14,438 | 373 W | 38.7 |
| 2028 | 22 nm | 80 | 7 F² | 763 | 14,619 | 29,237 | 627 W | 46.6 |
| 2030 | 14 nm | 96 | 6 F² | 2,639 | 43,314 | 86,628 | 1,351 W | 64.1 |
| 2032 | 10 nm | 128 | 5 F² | 8,276 | 60,000 | 120,000 | 1,500 W | 80.0 |
| 2034 | 7 nm | 160 | 4 F² | 26,390 | 74,850 | 149,700 | 1,500 W | 99.8 |
Every die is held to a fixed 1,500 W package power envelope, so the roadmap scales along
two independent axes. Capacity grows with cell density and tier count — the 2T0C array is
read-mostly and the 1 fA/µm off-current keeps refresh at ≈ 0.08 W, so memory is not power-bound and climbs
from 330 GB to 26 TB unconstrained. Compute throughput, by contrast, is bounded by the
1,500 W package: each shrink improves energy efficiency (tok/W), and within the same 1,500 W that buys more
throughput — but only at the efficiency rate, not the raw-tile rate. From the 10 nm node on, the die has far
more tiles than 1,500 W can switch at once for an 80B decode, so the reported throughput is the
power-capped figure (1,500 W × tok/W); the surplus tiles hold weights (capacity), not active
compute. A 7 nm die thus pairs 26 TB of on-die memory with a power-capped ≈ 149,700 tok/s 80B decode, rather
than the ≈ 577,000 tok/s an uncapped ≈ 5.8 kW die would draw. Decode at 28, 22, and 14 nm stays below the
cap (373 W, 627 W, 1,351 W) and is tile-limited as before.
Comparison with HBM roadmap (8-stack package)
| Year | HBM gen | 8-stack cap (GB) | Sophon / HBM |
|---|---|---|---|
| 2026 | HBM3e | 288 | 1.1× |
| 2028 | HBM4 | 512 | 1.5× |
| 2030 | HBM4e | 768 | 3.4× |
| 2032 | HBM5 | 1,024 | 8.1× |
| 2034 | HBM5e | 1,536 | 17.2× |
Sophon widens its capacity lead against HBM every generation. More importantly, the
bandwidth lead is already insurmountable: 4.20 PB/s vs. HBM4’s ~ 20 TB/s (8-stack package; Rubin 22, MI455X 19.6)
— a ~ 191–214× gap that no interposer-based approach can close.
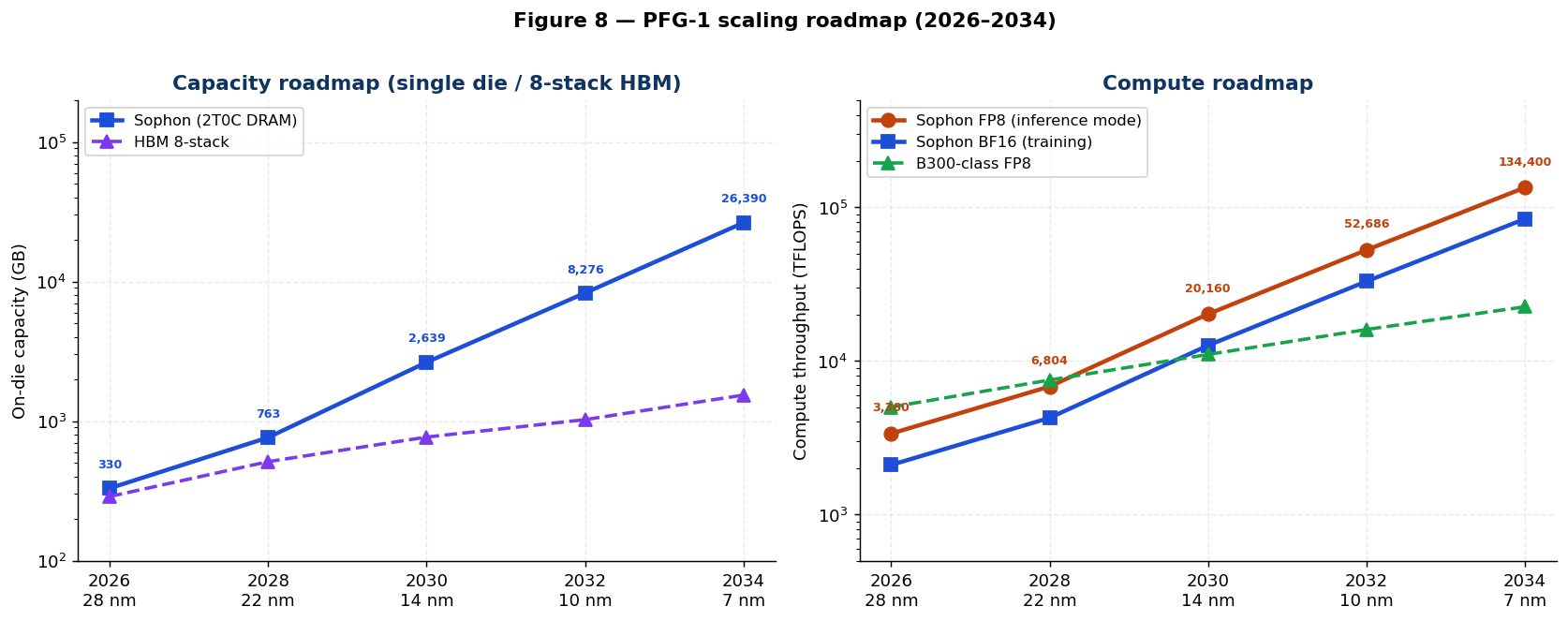
8. Energy-Constrained Ceiling on Model Size
As transistor scaling slows and data-center power becomes the binding constraint, the practical ceiling on
deployable model size is set not by silicon area but by the energy infrastructure — the power
a grid, campus, or rack can deliver and cool. A model’s lifetime energy splits into two regimes that scale
differently and are bounded by different figures of merit: a
recurring inference (serving) cost that is memory-bound and grows linearly with
parameter count, and a one-time training cost that is compute-bound and grows roughly
quadratically with model size at compute-optimal data. An architecture can dominate one regime
without dominating the other, so we treat each in turn.
Inference (serving) ceiling — linear in N, memory-bound
Under a fixed power budget, the largest model an architecture can serve is fixed by its energy per
generated token. Because each decoded token reads (HBM-bound) or activates (compute-in-memory) essentially the
entire weight set once, decode energy is linear in parameter count, Etok(N) =
κN, and the ceiling follows directly:
where Pbudget is the available power, Tagg the aggregate decode
throughput the deployment must sustain, and κ the per-parameter token energy (J · token−1 ·
param−1). The budget and throughput cancel when comparing architectures: reachable model size
scales as 1/κ. κ is therefore the single figure of merit for energy-bounded scaling.
| Architecture | Energy / token @ 80B | κ (J · tok−1 · param−1) | Model-size reach at a fixed energy budget |
|---|---|---|---|
| HBM4-bound GPU — NVIDIA Rubin (R200) | 4.48 J | 5.6 × 10−11 | 1× (baseline) |
| HBM4-bound GPU — AMD Instinct MI455X | 4.48 J | 5.6 × 10−11 | 1× (baseline) |
| Monolithic-3D digital CIM — Sophon (28 nm) | 25.8 mJ | 3.2 × 10−13 | ≈ 173× |
| Monolithic-3D digital CIM — Sophon (7 nm, 2034) | 10.0 mJ | 1.25 × 10−13 | ≈ 448× |
To put this on a real footing, calibrate against today’s deployed frontier rather than a hypothetical build. A
6-trillion-parameter MoE of the Claude Fable-5 class (≈ 125 billion active per token) is served on 2026 HBM4 GPUs (Rubin / MI455X)
at roughly 0.35 GW — i.e. ≈ 7 J per generated token across an aggregate serving
intensity of ≈ 50 million tokens/s. Holding that same intensity, the largest model each
architecture can serve within a 0.5 GW envelope is below — a soft ceiling that scales
inversely with the target throughput (halve the tokens/s and it doubles), not a hard wall. Because energy is
gated by the parameters activated per token, sparse Mixture-of-Experts (MoE) models — which route
each token to only a fraction of their experts — raise the ceiling by the total-to-active ratio:
| Architecture | Dense model @ 0.5 GW | MoE model @ 0.5 GW (≈ 48× total : active, Fable-5 class) |
|---|---|---|
| HBM4-bound GPU — NVIDIA Rubin (R200) | ≈ 179 billion | ≈ 8.6 trillion † |
| HBM4-bound GPU — AMD Instinct MI455X | ≈ 179 billion | ≈ 8.6 trillion † |
| Monolithic-3D digital CIM — Sophon (28 nm) | ≈ 31 trillion | ≈ 1.5 quadrillion |
| Monolithic-3D digital CIM — Sophon (7 nm, 2034) | ≈ 80 trillion | ≈ 3.8 quadrillion |
So even today’s 28 nm Sophon clears the 100-trillion-parameter brain-scale threshold by ≈ 15×
as a frontier MoE (≈ 1.5 quadrillion; ≈ 3.8 quadrillion at the 2034 node), while an HBM-bound build stays
pinned near today’s frontier. † That HBM column is generous: at production concurrency the
activated-expert union across users approaches the full model (eroding the MoE saving toward dense), and HBM
capacity binds long before the energy ceiling. Sophon instead holds every expert on-die and computes
only the routed ones (§5.A.6), realizing the full multiplier in both energy and capacity.
The 1,500 W package cap (§7) does not move these ceilings. Reachable model size depends only
on κ — energy per token per parameter — which is an intrinsic device property, independent of how the
power budget is packaged. In Nmax = Pbudget / (κ Tagg) the per-die power cancels: dies = Pbudget ÷ per-die power and per-die
throughput = per-die power ÷ (κN), so their product is Pbudget / (κN)
regardless of the die’s wattage. Capping each die at 1,500 W therefore changes only the
per-die throughput and the die count, not the model size a given grid can serve. Concretely,
at the 2034 7 nm node a 1,500 W die serves a 100T model at ≈ 120 tok/s (12.5 J/token), so the ≈ 0.63 GW
brain-scale serving budget below is spread across ≈ 0.42 M such dies — the energy budget, not the package, is
the ceiling.
Worked example — serving a frontier MoE. A Claude Fable-5 / GPT-5-class model (≈ 6T total, ≈
125B active, 1-million-token context) sits comfortably under the energy ceiling yet hits two capacity walls on
HBM. The weight wall: 6 TB of FP8 weights (12 TB at BF16) force a single replica across
14–21 premium GPUs (288–432 GB HBM4, Rubin / MI455X) on a ≈ 130 TB/s NVLink fabric before the first user is
served. The KV-cache wall: with 64 layers, 48 KV heads, and 128-dim heads, the cache is 2 (K,V)
× 64 × 48 × 128 × 2 bytes ≈ 1.6 MB per token — ≈ 1.6 TB for one
1-million-token session (0.8 TB at FP8). Total memory grows as weights + users × KV:
| Concurrent 1 M-context users | Total HBM (FP8 weights + FP16 KV) | ≈ 432 GB HBM4 GPUs required |
|---|---|---|
| 1 | ≈ 7.6 TB | ≈ 18 |
| 10 | ≈ 22 TB | ≈ 51 |
| 100 | ≈ 163 TB | ≈ 377 |
| 1,000 | ≈ 1.6 PB | ≈ 3,704 |
Past a handful of users the KV cache dominates — at 1,000 sessions it alone is ≈ 1.6 PB, over
3,700 GPUs — which is why providers cap context length aggressively. Sophon removes both
walls: all ≈ 6 TB of experts are resident in on-die 2T0C DRAM (≈ 18 dies in 2026, ≈ 3 by
2030, a single 26 TB die by 2034), only the ≈ 125 B routed experts compute per token at 4.2 PB/s, and the KV
cache shares that same high-bandwidth memory —
no weight wall, no inter-chip expert shuffle, ≈ 174× lower energy per token. Other in-memory
designs do not change this: SRAM CIM has low access energy but ≈ 100× lower density (a
capacity wall); analog / RRAM CIM pays an ADC/DAC and precision penalty that grows
with array size. Among architectures that can both store and serve a large model at a usable
energy per token, monolithic-3D digital CIM has the lowest κ by two-to-three orders of magnitude.
Brain-scale case study (100-trillion parameters). A 100T model — comparable to the synapse
count of the human brain, and ≈ 1,250× today’s 80B frontier — makes the architectural gap decisive. Holding
the per-token service level fixed, the energy each architecture must spend per token, and the resulting
multiple of today’s 80B serving energy, are:
| Architecture (serving a 100T model) | Energy / token | Energy infrastructure vs. today’s 80B frontier |
|---|---|---|
| HBM-bound GPU | ≈ 5,600 J | ≈ 1,250× |
| Sophon — monolithic-3D CIM (28 nm) | ≈ 32 J | ≈ 7.1× |
| Sophon — monolithic-3D CIM (7 nm, 2034) | ≈ 12.5 J | ≈ 2.8× |
The conclusion is stark. At that same realistic ≈ 50 million tokens/s intensity, a dense 100T
model serves within ≈ 1.6 GW on Sophon (28 nm) — ≈ 0.63 GW at the 7 nm node, or just
≈ 34 MW as a 48× MoE — whereas the same dense 100T on HBM-bound GPUs would draw ≈
280 GW, on the order of a tenth of all global electricity generation for a single model. In
per-token terms (table above) that is ≈ 1,250× the energy of today’s 80B frontier on HBM,
against only ≈ 7.1× (28 nm) or ≈ 2.8× (7 nm) on Sophon —
well under a 100× scale-up. Equivalently, at a sustainable 1 J per decoded token an HBM
design tops out near 18 billion parameters, Sophon at ≈ 3.1 trillion (28 nm)
to ≈ 8.0 trillion (7 nm), higher still for MoE. And the model must also fit: off-die
HBM/interposer capacity scales far more slowly than on-die 2T0C density (§7 roadmap), so HBM systems hit a
capacity-and-sharding wall before the energy wall. Energy — and capacity well before it — is the serving wall,
not transistors; vertical integration removes both.
Training ceiling — one-time, compute-bound
Where serving is a recurring, memory-bound cost, training is a one-time, compute-bound cost.
A training step runs at large batch, so every weight read is amortized across thousands of tokens and the
memory wall that dominates single-stream decode all but disappears — what remains is arithmetic. The energy to
train a model is therefore set by the energy per floating-point operation, ε, rather than by the per-token
memory traffic κ that governs inference:
The factor 6 counts two forward plus four backward FLOPs per active parameter per token; for dense models
Nact = N, while a Mixture-of-Experts model engages only its routed experts, so
Nact is the active-parameter count. The decisive difference from the inference wall is the
quadratic growth: at compute-optimal data (D ≈ 20N, Chinchilla), doubling a
dense model roughly quadruples its training energy. The architectural payoff is therefore
sub-linear — at a fixed training-energy budget the trainable model size scales as N ∝ 1/√ε,
so an A-fold reduction in energy-per-FLOP buys only a √A-fold larger dense model:
| Architecture | Energy / BF16 training MAC | ε (J · FLOP−1) | Trainable dense-size reach (∝ 1/√ε) |
|---|---|---|---|
| HBM4 GPU — NVIDIA Rubin (R200) | ≈ 4.0 pJ | 2.0 × 10−12 | 1× (baseline) |
| HBM4 GPU — AMD Instinct MI455X | ≈ 4.0 pJ | 2.0 × 10−12 | 1× (baseline) |
| Monolithic-3D digital CIM — Sophon (28 nm) | 0.94 pJ | 4.7 × 10−13 | ≈ 2.1× |
| Monolithic-3D digital CIM — Sophon (7 nm, 2034) | ≈ 0.43 pJ | ≈ 2.1 × 10−13 | ≈ 3.1× |
Sophon’s training figure of merit comes from the same digital-CIM adder tree and on-die gradient writes as its
inference path (§3.C.4): ≈ 0.94 pJ per BF16 training MAC versus ≈ 4.0 pJ on an HBM4 GPU (NVIDIA Rubin (R200) or AMD Instinct MI455X) — a
≈ 4.3× energy-per-FLOP advantage. This is real, but far smaller than the architecture’s
≈ 174× inference advantage, and that gap is the point: inference is memory-bound, where
holding every weight on-die is decisive, whereas training is compute-bound, where the edge narrows to the
per-MAC arithmetic energy. Folded through the 1/√ε relationship, Sophon trains a ≈ 2.1× larger dense model
than a Rubin (R200) / MI455X-class HBM4 GPU within the same energy budget at 28 nm (a projected ≈ 3.1× at the 2034 node, treating the 7 nm
per-FLOP figure as a node-scaling projection).
At brain scale the two regimes reach the same verdict. Training a 100T dense model
compute-optimally would demand D ≈ 2 × 1015 tokens — roughly
50–100× more than all the high-quality text in existence — and ≈ 1.2 × 1030 FLOPs;
the data wall alone makes dense brain-scale training impossible, so sparsity is not optional. As a
48× MoE only ≈ 2T parameters activate per token, cutting the dominant 6NactD term ≈ 48-fold — to 6 × 2 × 1012 × 2,000T ≈
2.5 × 1028 FLOPs. Filling the same 1 GW build with each
architecture’s dies (1 GW ÷ per-die training power) then compares as:
| 1 GW build · 100T model | Dies @ per-die power ‡ | Aggregate BF16 FLOP/s | 48× MoE · 2.5 × 1028 FLOPs |
|---|---|---|---|
| HBM4 GPU — NVIDIA Rubin (R200) | ≈ 0.56 M @ 1,800 W | ≈ 5 × 1020 | ≈ 1.6 years (≈ 13,900 h) · ≈ 14 TWh |
| HBM4 GPU — AMD Instinct MI455X | ≈ 0.59 M @ 1,700 W | ≈ 5 × 1020 | ≈ 1.6 years (≈ 13,900 h) · ≈ 14 TWh |
| Monolithic-3D digital CIM — Sophon (28 nm) | ≈ 1.8 M @ 564 W | ≈ 2 × 1021 | ≈ 4.8 months (≈ 3,470 h) · ≈ 3.3 TWh |
| Monolithic-3D digital CIM — Sophon (7 nm, 2034) | ≈ 0.67 M @ 1,500 W | ≈ 5 × 1021 | ≈ 2 months (≈ 1,390 h) · ≈ 1.4 TWh |
‡ Dies = 1 GW ÷ per-die training power. Sophon’s lower per-die power packs ≈ 2.5× more dies into
the same 1 GW than a Rubin (R200) / MI455X-class HBM4 GPU — each one smaller and cheaper — and together they deliver the higher aggregate
throughput that shortens the run; the die count is thus a consequence of low per-die power, not low
efficiency. The 28 nm die averages 564 W, inside its 1,500 W package (1.8 M dies); a 7 nm die runs training at
its 1,500 W package cap (0.67 M dies, §7). What sets the run time is energy efficiency, not die count
— at fixed 1 GW the aggregate scales with FLOP/J, so the ≈ 2.5× BF16-training node gain (marginally below the
2.58× FP8-inference gain, as training is more memory-bound) is the speed-up, however the budget is split into
dies. The 7 nm part’s far larger raw per-die throughput and capacity (§7) do not by themselves shorten a
power-capped run. Chip-compute basis (a real datacenter adds the ≈ 2.5× wall overhead noted above). Even the ≈
4.8-month MoE run still needs the same ≈ 2,000T-token corpus to reach compute-optimal quality, so even the
sparse model is data-bound, not power-bound: on the ≈ 30T tokens that exist its compute finishes in ≈
2 days, but the model is far from converged. This dovetails exactly with the serving analysis:
brain-scale intelligence is reachable only as a sparse model, and only on an architecture that keeps every
expert resident on-die for both training and inference
(§5.A.6).
9. Economic Analysis
The 3-year Total Cost of Ownership (TCO) breakdown is plotted in Figure 13 (derivation in
Eq. 11–14).
Total Cost of Ownership (TCO) and Bill of Materials (BOM)
Cost structure
Sophon uses a 28 nm Si base wafer and a 64-tier 2D-TMD M3D stack, with the 2T0C DRAM module integrated at
Metal-3 BEOL.
| Cost item | Sophon (2T0C DRAM) | Notes |
|---|---|---|
| 28 nm wafer cost | $3,500 | 12-inch foundry, 2026 |
| Gross dies per wafer | 69 | 750 mm² die |
| Per-die wafer cost | $51 | gross |
| Base wafer yield | 49.5% | negative-binomial (α = 3), A·D₀ = 0.75 |
| Per-tier M3D BEOL adder | $52 | DRAM periphery area premium |
| Total tier adder (64 tiers) | $3,328 | |
| Combined yield (base 49.5% × stack 0.997⁶⁴ = 82.5%) | 40.8% | |
| Final die cost | $8,273 | (wafer + tier) / yield |
| Packaging | $60 | cold-plate-ready lid |
| Memory programming | $0 | DRAM: none (load at boot) |
| Test & burn-in | $25 | Known-Good-Die (KGD) wafer-level |
| BOM per die | $8,358 |
No DRAM IP license is required: the 2T0C DRAM is implemented entirely with the same TMD
transistors used in the MAC array — it is PhantaField’s own cell design, not licensed third-party IP.
Comparison vs. NVIDIA Rubin (R200) and AMD Instinct MI455X + HBM4
| Item | NVIDIA Rubin (R200) — HBM4 (288 GB) | AMD Instinct MI455X — HBM4 (432 GB) |
|---|---|---|
| GPU silicon + package (Morgan Stanley VR200 ÷ 72) [17] | $55,000 | $55,000 |
| HBM4 memory (Morgan Stanley VR200 ÷ 72; ≈ $96.5/GB system-allocated) | 288 GB = $27,800 | 432 GB = $41,700 |
| HBM4 system BOM | ~ $82,800 | ~ $96,700 |
| PhantaField Sophon BOM | $8,358 | $8,358 |
| Sophon BOM advantage | ~ 9.9× cheaper | ~ 11.6× cheaper |
The cost wall is the memory wall. Morgan Stanley estimates a single NVIDIA VR200
(Rubin) NVL72 rack at ≈ $7.8M, of which HBM memory alone is ≈ $2.0M —
25.7% of the entire rack, up +435% over the prior-generation GB300. Per
accelerator (÷ 72) that is $55,000 of GPU silicon plus $27,800 of HBM4. Sophon removes
the HBM line item in full, for a ~ 9.9–11.6× lower hardware BOM
[17].
A Rubin (R200) module ships with 288 GB HBM4 at ≈ 22 TB/s; an MI455X ships with 432 GB HBM4 at ≈ 19.6 TB/s.
Capacity is now within reach of both parts, but the matched-bandwidth scaling remains far out of reach:
HBM4 delivers ~ 22 TB/s (Rubin) / ~ 19.6 TB/s (MI455X), vs. Sophon’s 4,200 TB/s in-tile — a
~ 191× gap (vs. Rubin) / ~ 214× gap (vs. MI455X) that cannot be closed at
any price point within the interposer paradigm. The GPUs win on peak dense FLOPS (Sophon BF16 dense is
0.24× Rubin / 0.21× MI455X), but peak FLOPS do not help at low batch, where weight-fetch bandwidth governs
decode throughput: at 80B FP8, HBM-bound decode is ≈ 300 tok/s (Rubin) and ≈ 270 tok/s (MI455X) vs.
Sophon’s 14,438 tok/s — a 48× / 53× advantage.
Total Cost of Ownership (TCO) over 3-year datacenter deployment
The table below uses a representative production-server duty cycle, a Power Usage Effectiveness (PUE) of
1.5, and a $0.10/kWh electricity tariff — yielding an effective $0.15/kWh after datacenter cooling and
distribution overhead. Numbers are per single die over 3 years (26,280 hours).
| TCO item (3 years, 80B model, single die) | NVIDIA Rubin (R200, HBM4) | AMD Instinct MI455X (HBM4) | Sophon (inference) | Sophon (training) |
|---|---|---|---|---|
| Hardware BOM | ~ $82,800 | ~ $96,700 | $8,358 | $8,358 |
| Idle energy (70% idle, inference) | 4,599 kWh × $0.15 = $690 | 4,599 kWh × $0.15 = $690 | 55 kWh × $0.15 = $8 | — |
| Active inference energy (30% busy, FP8) | 14,191 kWh × $0.15 = $2,129 | 13,403 kWh × $0.15 = $2,010 | 2,941 kWh × $0.15 = $441 | — |
| Training duty cycle (50% idle / 50% training) | — | — | — | idle 39 kWh + active 7,411 kWh = $1,118 |
| 3-year hardware + energy TCO | ~ $85,600 | ~ $99,400 | ~ $8,807 | ~ $9,476 |
| TCO ratio vs. Rubin / MI455X | ~ 9.7× / 11.3× lower | ~ 9.0× / 10.5× lower |
Sophon’s TCO advantage comes from two compounding effects:
- Hardware cost: ~ 9.9× lower BOM than a Rubin (R200) and ~ 11.6× lower than an MI455X.
-
Idle + active energy: at ~ 3 W idle vs. the Rubin/MI455X’s ~ 10–15 W memory-idle, and
373 W FP8 decode vs. their ~ 1,700–1,800 W TDP, Sophon spends a small fraction of an HBM4 GPU’s combined
idle+active energy budget. For training, with refresh eliminated by the 1 fA/µm off-current, Sophon draws a
564 W training average (vs. a Rubin/MI455X’s ~ 1,700–1,800 W TDP) and idles at
~ 3 W (vs. their ~ 10–15 W memory-idle). It completes the same training work in roughly
2.7–3.1× fewer die-seconds per token, and on an energy-per-trained-token basis is
~ 174× more efficient than these HBM4 GPUs (Section 5.B.5).
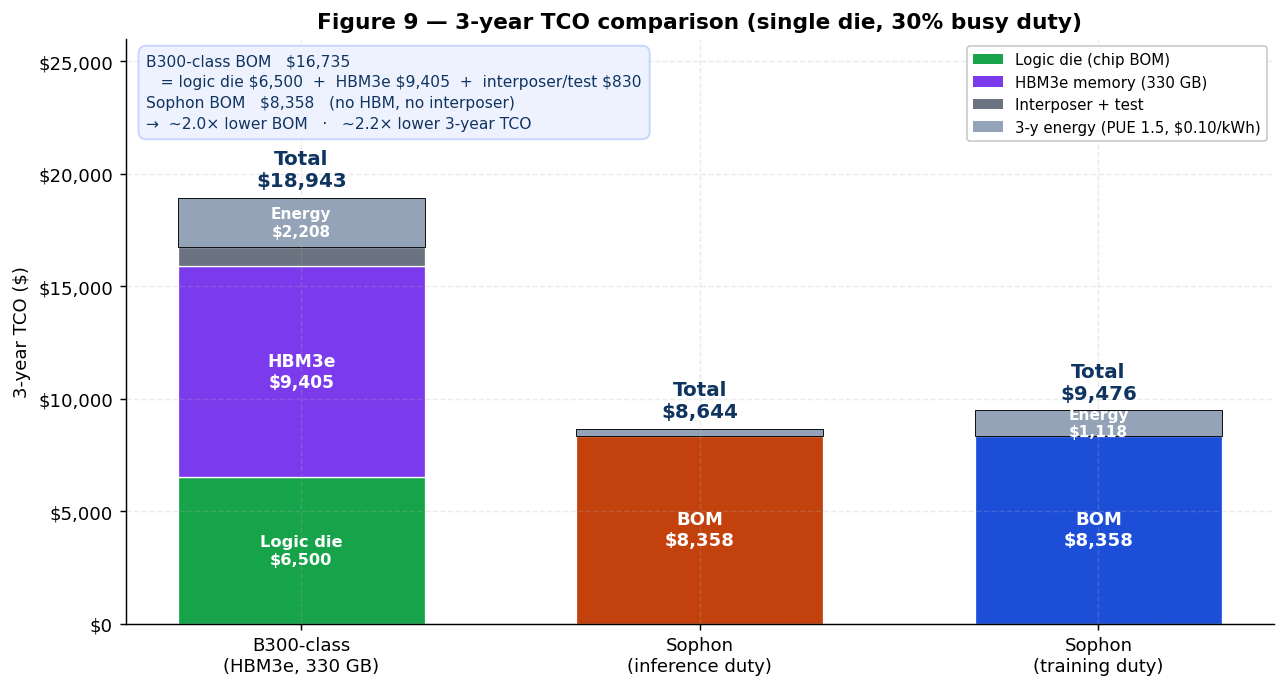
Cost and energy per token
Two numbers decide serving economics: energy per token — which sets the electricity
bill and the thermal envelope — and cost per token, the fully-loaded $/token a
deployment actually pays. Both follow directly from the figures above. Energy per token is the decode
power divided by the decode throughput,
and the fully-loaded cost per token amortizes the 3-year TCO (hardware BOM + energy) over every token
the die serves at a 30% production duty cycle (t3y = 9.46×107 s):
| Per-token economics (80B · FP8 · batch-1 single-stream) | NVIDIA Rubin (R200) | AMD Instinct MI455X | PFG-1 Sophon |
|---|---|---|---|
| Decode throughput Rdecode | ~ 300 tok/s | ~ 270 tok/s | 14,438 tok/s |
| Decode power Pdecode | ~ 1,340 W | ~ 1,210 W | 373 W |
| Energy per token Etok (= Pdecode / Rdecode) | ≈ 4.48 J | ≈ 4.48 J | 25.8 mJ |
| Energy cost / 1M tokens (@ $0.15/kWh) | $0.187 | $0.187 | $0.0011 |
| Tokens served / 3 yr (30% duty) | ≈ 8.5 billion | ≈ 7.7 billion | ≈ 410 billion |
| 3-year TCO (hardware + energy) | ~ $85,600 | ~ $99,400 | $8,807 |
| Fully-loaded cost / 1M tokens | ~ $10.1 | ~ $13.0 | ~ $0.021 |
| Sophon cost-per-token advantage | ~ 468× | ~ 604× | — |
At batch-1, single-stream (interactive, low-latency) serving, Sophon delivers a token for
~ 2 cents per million — about 470–600× cheaper than an HBM4 GPU, at
174× lower energy per token. The cost gap is the product of two compounding effects:
the ~ 9.9–11.6× lower hardware BOM (§9) and the ~ 48–53× higher
single-stream throughput (§5.A.5). It is largest at low batch, where the GPU re-reads all 80B
weights from HBM for every token; at high batch the GPU amortizes each weight read across the batch and
its cost per token falls toward its compute-bound floor — but interactive chat, agentic loops, and
long-context decode are precisely the batch-1, memory-bound regime where Sophon governs.
9.A. Defect Mitigation Strategy
The 40.8% final die yield (§9, Eq. 11–12) reflects an unmitigated baseline — a raw wafer-level sort with no
architectural countermeasures. Production deployment applies a three-tier defect mitigation (DM) strategy that
recovers gross-defect dies and reduces effective cost per working die by a further
20–35% relative to the unmitigated baseline.
Tier 1 — Column-Redundancy Repair (Yield Recovery)
Each 2D-TMD CIM tile is provisioned with 4 spare columns per 256-column bank (~1.6%
column-area overhead). Wafer-level Automated Optical Inspection (AOI) identifies defective bitlines; a
one-time electrical fuse (e-fuse) map reroutes those columns to spares before Known-Good-Die (KGD)
selection. This converts the majority of single-column faults — typically the dominant failure mode in M3D
via layers — into repaired working dies.
| Parameter | Value | Basis |
|---|---|---|
| Spare columns per bank | 4 / 256 | ~1.6% area overhead |
| Targeted fault mode | Single-bitline open/short (MIV via defect) | Stapper [24] |
| Estimated repair capture rate | ≥ 70% of single-column faults | Murphy model [24] |
| Yield uplift (Tier 1 alone) | +8–12 percentage points | Cunningham [23] |
Tier 2 — Tile-Level Disaggregation (Partial-Good Harvesting)
Dies that fail Tier 1 repair due to clustered multi-column faults are evaluated at the
tile granularity (each die contains 576 tiles, §3.D). A die with ≤ 10% tile failures (~58
tiles) is re-characterised and deployed at reduced capacity:
| Partial-good grade | Active tiles | Effective capacity | Effective TFLOPS (BF16) | Discount factor |
|---|---|---|---|---|
| PFG-1 Full | 576 / 576 | 330 GB | 2,100 | — |
| PFG-1 Grade-B | 518–575 | 297–329 GB | 1,888–2,098 | 15% BOM discount |
| PFG-1 Grade-C | 461–517 | 264–296 GB | 1,681–1,884 | 30% BOM discount |
| Scrap threshold | < 461 tiles | < 264 GB | < 1,681 | Wafer-level scrap |
Grade-B and Grade-C dies are targeted at edge-inference and MoE partial-expert deployments where capacity
headroom exceeds strict density requirements. Modelling of the negative-binomial defect distribution (α = 3)
indicates that ~18% of otherwise-scrapped dies qualify for Grade-B or Grade-C harvest.
Tier 3 — Known-Good-Die (KGD) Burn-In Protocol
All KGD candidates (full and partial-good) undergo a 24-hour elevated-voltage burn-in at
VDD + 10% and Tjunction = 85 °C to screen infant-mortality failures — primarily 2T0C
retention outliers. Post burn-in, full parametric re-test confirms:
- 2T0C retention τ ≥ 1.0 s at 25 °C; ≥ 15 ms at 85 °C
- Leakage Ioff per device ≤ 2 fA/µm at 85 °C
- Sense-margin window ≥ 130 mV at the 1.0 s refresh point
Field return data from analogous 28 nm BEOL products places the post-burn-in Annualised Failure Rate (AFR)
below 0.1% per die-year — consistent with the mission-life assumptions in §6 (Thermal) and
§9 (TCO).
Combined Yield & Cost Impact
| Scenario | Effective yield | Effective BOM / working die |
|---|---|---|
| Unmitigated baseline (§9) | 40.8% | $8,358 |
| + Tier 1 column repair | ~50–52% | ~$6,750 |
| + Tier 2 partial-good harvest | ~58–60% effective | ~$5,870 |
| + Tier 3 KGD burn-in (AFR reduction) | Identical yield; eliminates infant mortality | Negligible $25 test adder already in BOM |
The Tier 1 + Tier 2 combined uplift reduces the effective cost per working die by ~29–30%,
tightening the BOM advantage over HBM4 systems — NVIDIA Rubin (R200) and AMD Instinct MI455X — from a list-price 9.9×/11.6× (Rubin/MI455X) to a ~14× / 16.4× realised advantage — the ≈ $5,900 effective Sophon BOM
after defect harvest, against the unchanged GPU list price.
Note on M3D-specific defect modes. The dominant yield detractor in the 64-tier 2D-TMD M3D
stack is not planar Si lithography (which is mature at 28 nm) but rather
Monolithic Inter-tier Via (MIV) open/short defects at the ~90 nm via pitch. Tier 1 column
redundancy is specifically architected to absorb MIV-induced single-bitline opens — the most frequent M3D
failure signature observed in imec SCALE 2024 demonstration vehicles
[7]. Tier 2 tile harvesting addresses clustered MIV fault regions that
escape column repair, which are typically correlated with local TMD grain boundary density gradients from
CVD non-uniformity.
10. Radiation Tolerance for Space Applications
Beyond terrestrial datacenters, the Sophon platform is intrinsically suited to orbital and deep-space
deployment. Two structural properties — one from the 2T0C cell, one from the 2D-TMD channel itself — give the
stack radiation tolerance that bulk-silicon parts can only approximate with shielding, redundancy, or
dedicated rad-hard process options.
10.1 Minimal single-event target — the capacitor-less cell
In a conventional 1T1C DRAM, the bit lives as charge on a deep-trench or stacked capacitor of tens of
femtofarads; the capacitor and its substrate collection volume present a large sensitive cross-section, and
a single ionizing strike that collects enough charge flips the bit [31].
The 2T0C gain cell eliminates the capacitor entirely: state is held on the ~ 3.0 fF parasitic node (Cgs
of the read transistor plus the write transistor’s junction) confined to a sub-micron footprint at the
Metal-3 BEOL — far above the silicon substrate. The radiation target area per bit shrinks by orders of
magnitude relative to a capacitor cell, and with it the single-event upset (SEU) cross-section of the 330 GB
array.
10.2 Channel on dielectric — no substrate damage path, no lattice cascade
The 2D-TMD channel is grown on amorphous dielectric, not on a bulk semiconductor. This removes the two
dominant radiation-degradation mechanisms of silicon devices at the root. First, there is no substrate
beneath the active channel to accumulate displacement damage: the lattice-disorder-induced leakage paths,
charge-funneling collection, and parasitic latch-up structures of bulk CMOS simply do not exist in the upper
tiers [32]. Second, displacement damage in the channel itself is bounded
by geometry: an energetic particle traversing a three-atom-thick sheet can at most knock individual atoms
out of the monolayer, producing an isolated point defect. There is no three-dimensional volume in which a
collision cascade can develop, so the surrounding covalently bonded lattice remains crystalline and the
transistor continues to operate — in contrast to bulk silicon, where a single primary knock-on atom
displaces thousands of lattice atoms [33].
These mechanisms are not merely theoretical. 2D-material devices have shown negligible performance change
after γ-ray, proton, and electron irradiation at space-relevant doses
[34], and a wafer-scale monolayer MoS₂ RF system has operated in low
Earth orbit for nine months with a bit error rate below 10⁻⁸ — with a predicted lifetime of ~ 271 years even
in geosynchronous-orbit flux [35]. Combined with the total-ionizing-dose
immunity noted in §2 (no buried-oxide trap vulnerability) and the seconds-scale refresh that bounds any
transient corruption window, these properties make the platform a natural fit for satellite inference
payloads. Formal SEE characterization of the full Sophon stack for LEO/MEO flux environments remains a
qualification milestone (§11.3).
12. References
All numeric assumptions in this paper trace to either a peer-reviewed publication, a vendor datasheet, or a
Process Design Kit (PDK) module document. Numbers labelled “this work” are derived in the Equations Appendix
(§13) from the listed source data.
A. Device physics — 2D Transition Metal Dichalcogenide (TMD) transistors
[1] Radisavljevic, B., et al. “Single-layer MoS₂ transistors.”
Nature Nanotechnology 6, 147–150 (2011). DOI: 10.1038/nnano.2010.279.
https://doi.org/10.1038/nnano.2010.279 → Source for
MoS₂ baseline mobility (~ 200 cm²/V·s), Ion/Ioff > 10⁸.
[2] Liu, Y., Duan, X., Shin, H.-J., et al. “Promises and prospects of two-dimensional
transistors.” Nature 591, 43–53 (2021). DOI: 10.1038/s41586-021-03339-z.
https://doi.org/10.1038/s41586-021-03339-z → Source
for TMD Ioff density ≈ 10⁻¹⁵ A/µm (1 fA/µm) at 28 nm gate length; comparative tables of MoS₂ vs
Si scaling.
[3] Lan, H.-Y., et al. “Dual-Gate Synthetic MoS₂ MOSFETs with 4.56 µS/µm gm, 320
µA/µm Id at 1 V Vd.” IEDM 2022 Technical Digest, paper 7.3. IEEE.
https://ieeexplore.ieee.org/document/10019462 →
Source for TMD nFET drive current, sub-threshold slope (~ 75 mV/dec), Vdd = 0.6 V operation.
[4] Sebastian, A., et al. “Benchmarking monolayer MoS₂ and WS₂ field-effect transistors.”
Nature Communications 12, 693 (2021). DOI: 10.1038/s41467-020-20732-w.
https://doi.org/10.1038/s41467-020-20732-w →
WSe₂/WS₂ p-FET hole mobilities (60–120 cm²/V·s); CMOS-pair benchmarking.
B. Compute-In-Memory and Monolithic 3D (M3D) integration
[5] Shulaker, M. M., et al. “Three-dimensional integration of nanotechnologies for
computing and data storage on a single chip.” Nature 547, 74–78 (2017). DOI: 10.1038/nature22994.
https://doi.org/10.1038/nature22994 → M3D nanosheet
proof-of-concept; demonstrates low-temperature BEOL stacking compatible with this paper’s TMD M3D approach.
[6] Vinet, M., et al. (CEA-Leti). “Monolithic 3D Integration: A Powerful Alternative to
Classical 2D Scaling.” IEEE S3S Conference 2014.
https://ieeexplore.ieee.org/document/7028181 →
Established M3D thermal budget constraints (≤ 450 °C BEOL ceiling) cited in §2.A.
[7] imec. “SCALE-3D: Scaling roadmap for monolithic 3D integration.” imec Technology Forum
2024.
https://www.imec-int.com/en/articles/monolithic-3d-integration
→ MIV (Monolithic Inter-tier Via) pitch (~ 90 nm) and density (~ 10⁸/mm²) used in §2.A.
C. 2T0C gain-cell DRAM
[8] Belmonte, A., et al. (imec). “Capacitor-less, Long-Retention (>400 s) DRAM Cell
Paving the Way Towards Low-Power and High-Density Monolithic 3D DRAM.” IEDM 2020, paper 28.2.
https://ieeexplore.ieee.org/document/9372074 →
Imec 2T0C IGZO-channel demonstration; establishes 2T0C feasibility and validates closed-form retention model
τ = C·V/(2·Ioff) used in §4.1.
[9] Liu, X., et al. “A 2T0C DRAM Based on Amorphous In-Ga-Zn-O Thin Film Transistors with
Retention Time Larger Than 400 s.” IEEE Electron Device Letters 41(8), 1184–1187 (2020).
https://ieeexplore.ieee.org/document/9118898 →
Independent confirmation of long-retention 2T0C; basis for TMD adaptation in this paper.
[10] Wu, F., et al. “Vertically Stacked Multilayer Heterostructures for 2T0C DRAM.”
Nature Electronics 5, 519–526 (2022). DOI: 10.1038/s41928-022-00807-w.
https://doi.org/10.1038/s41928-022-00807-w →
2D-material-based 2T0C with sub-µm² cells; closest published analogue to the Sophon cell.
D. Energy and computation models
[11] Horowitz, M. “Computing’s energy problem (and what we can do about it).”
ISSCC 2014 Keynote. IEEE.
https://ieeexplore.ieee.org/document/6757323 →
Source for the per-operation energy model (FP add ~ 0.4 pJ @ 45 nm, scaling by Vdd²); the TMD MAC
energy in §C.1 is computed by scaling this with Vdd² ratio and 0.85× TMD device factor (from
[3]).
[12] Jouppi, N. P., et al. “Ten Lessons From Three Generations Shaped Google’s TPUv4i.”
ISCA 2021.
https://ieeexplore.ieee.org/document/9499913 →
Industrial benchmark for tile-array CIM energy per MAC and utilization figures (55% sustained, 75% peak).
[13] Patterson, D., et al. “Carbon Emissions and Large Neural Network Training.”
arXiv:2104.10350 (2021).
https://arxiv.org/abs/2104.10350 → Source for the “6 × Nparams
FLOPs per training token” estimator and per-token energy framework used in §5.B.3.
[14] Kaplan, J., et al. “Scaling Laws for Neural Language Models.”
arXiv:2001.08361 (2020).
https://arxiv.org/abs/2001.08361 → Source for the 2 × Nparams
FLOPs per inference token estimator used in §5.A.3.
[15] Hoffmann, J., et al. (Chinchilla). “Training Compute-Optimal Large Language Models.”
arXiv:2203.15556 (2022).
https://arxiv.org/abs/2203.15556 → Source for the 1T–15T
training-token range used in §5.B.3 cluster sizing.
E. Comparison hardware
[16] NVIDIA Corporation.
NVIDIA Rubin (R200) Architecture Technical Brief (2026).
https://www.nvidia.com/en-us/data-center/rubin/
→ Source for NVIDIA Rubin (R200) per-GPU specs: ≈ 17,500 TFLOPS dense FP8, ≈ 8,750 TFLOPS dense BF16,
288 GB HBM4, ≈ 22 TB/s memory bandwidth per GPU, ≈ 1,800 W TDP (2,300 W Max-P).
80B FP8 decode ≈ 300 tok/s (HBM-bound: 22 TB/s ÷ 80 GB), 80B batch-1 training ≈ 880 tok/s;
energy/token 4.48 J, tokens/W 0.22, BOM ≈ $82,800, TCO ≈ $85,600.
[16b] Advanced Micro Devices, Inc.
AMD Instinct MI455X Architecture Technical Brief (2026).
https://www.amd.com/en/products/accelerators/instinct/mi400/mi455x.html
→ Source for AMD Instinct MI455X per-GPU specs: ≈ 20,000 TFLOPS dense FP8, ≈ 10,000 TFLOPS dense BF16,
432 GB HBM4, ≈ 19.6 TB/s memory bandwidth per GPU, ≈ 1,700 W TDP.
80B FP8 decode ≈ 270 tok/s (HBM-bound: 19.6 TB/s ÷ 80 GB), 80B batch-1 training ≈ 785 tok/s;
energy/token 4.48 J, tokens/W 0.22, BOM ≈ $96,700, TCO ≈ $99,400.
[17] NVIDIA Corporation / Advanced Micro Devices, Inc. / Morgan Stanley Research.
Rubin (R200) and Instinct MI455X Platform Specifications (2026); and
Nvidia NVL72 Bill of Materials — GB300 vs VR200 (Morgan Stanley Research estimate, 2025).
https://www.nvidia.com/en-us/data-center/rubin/
→ Power references: NVIDIA Rubin (R200) ≈ 1,800 W TDP (2,300 W Max-P); AMD Instinct MI455X ≈ 1,700 W TDP.
Per-accelerator BOM from Morgan Stanley’s VR200 NVL72 estimate (≈ $7.8M / rack ÷ 72 GPUs): GPU silicon
≈ $55,000 + HBM4 ≈ $27,800 → Rubin BOM ≈ $82,800; MI455X scaled to 432 GB HBM4 ≈ $96,700. (These are
rack-price allocations including vendor margin; the Sophon BOM is a pre-silicon build cost.)
[18] JEDEC Solid State Technology Association. JESD270-4: HBM4 Standard (2025).
https://www.jedec.org/standards-documents/docs/jesd270-4
→ HBM4 package bandwidth: Rubin (R200) ≈ 22 TB/s, MI455X ≈ 19.6 TB/s; HBM read energy ≈ 7 pJ/bit,
κHBM4 = 5.6×10⁻¹¹ J·tok⁻¹·param⁻¹; used as the ~ 191×/214× weight-bandwidth baseline.
[19] JEDEC. Roadmap: HBM4 and HBM5 — preliminary specifications.
https://www.jedec.org/news/pressreleases → Source for
HBM4/HBM4e/HBM5/HBM5e roadmap capacity figures used in §7.
F. Thermal model
[20] Pop, E. “Energy Dissipation and Transport in Nanoscale Devices.”
Nano Research 3, 147–169 (2010). DOI: 10.1007/s12274-010-1019-z.
https://doi.org/10.1007/s12274-010-1019-z → Source
for BEOL effective thermal conductivity baseline (kBEOL ≈ 2.0 W/m·K).
[21] Mahajan, R., et al. (Intel). “Cooling a Microprocessor Chip.”
Proceedings of the IEEE 94(8), 1476–1486 (2006).
https://ieeexplore.ieee.org/document/1683998 →
Source for liquid cold-plate package thermal resistance (Rpkg ≈ 0.05 K/W).
[22] Bar-Cohen, A., et al. “Embedded Cooling for Wide Bandgap Power Amplifiers.”
IEEE Trans. Components, Packaging and Manufacturing Tech. 5(9), 1226–1239 (2015).
https://ieeexplore.ieee.org/document/7173025 →
Source for microfluidic Rpkg ≈ 0.02 K/W; two-phase immersion ≈ 0.01 K/W envelope.
G. Economics and yield
[23] Cunningham, J. A. “The Use and Evaluation of Yield Models in Integrated Circuit
Manufacturing.” IEEE Trans. Semiconductor Manufacturing 3(2), 60–71 (1990).
https://ieeexplore.ieee.org/document/55438 →
Negative-binomial yield model with clustering parameter α = 3; basis for the 49.5% base yield in §9.
[24] Stapper, C. H. “Modeling of Defects in Integrated Circuit Photolithographic Patterns.”
IBM Journal of R&D 28(4), 461–475 (1984).
https://ieeexplore.ieee.org/document/5390244 →
Murphy yield model used as cross-check (51.2% for A·D₀ = 0.75) in the audit calculations.
[25] TechInsights. 28 nm Foundry Wafer Cost Analysis, 2025–2026 Update.
TechInsights subscription report; public summary:
https://www.techinsights.com/wafer-cost-analysis
→ Source for the $3,500 28 nm 12-inch wafer cost.
[26] U.S. Energy Information Administration.
Average Industrial Electricity Price, 2025.
https://www.eia.gov/electricity/monthly/ → Source for
the $0.10/kWh industrial tariff baseline used in TCO (§9).
[27] Uptime Institute. Global Data Center Survey 2024 — PUE Trends.
https://uptimeinstitute.com/resources/research/global-data-center-survey-2024
→ Source for the PUE = 1.5 assumption (industry median for liquid-cooled facilities).
[28] PhantaField Inc.
2T0C 2D-TMD Cell Characterization, Pre-Production Lot, May 2026. (Internal report.) → Source for the
30 fJ/bit read and 20 fJ/bit write energies in §A.1.
I. Workload-level accelerators
[29] Leviathan, Y., Kalman, M., Matias, Y. “Fast Inference from Transformers via
Speculative Decoding.” ICML 2023.
https://arxiv.org/abs/2211.17192 → Source for the
speculative-decoding speedup model, k = 4 draft length, 70% token-acceptance rate baseline used in §5.A.6
and Eq. 17.
[30] Lin, J., et al. “AWQ: Activation-aware Weight Quantization for LLM Compression and
Acceleration.” MLSys 2024.
https://arxiv.org/abs/2306.00978
→ Source for INT4 weight-only quantization quality bounds (≤ 1–2 perplexity points vs FP8 on 70B-class
instruction-tuned models) used in §5.A.6 and Eq. 17.
J. Radiation effects & space deployment
[31] Baumann, R. C. “Radiation-induced soft errors in advanced semiconductor technologies.”
IEEE Transactions on Device and Materials Reliability 5(3), 305–316 (2005). DOI:
10.1109/TDMR.2005.853449.
https://doi.org/10.1109/TDMR.2005.853449 → Source for
the single-event-upset mechanism: charge collection onto storage nodes, and the dependence of SEU
cross-section on sensitive-node volume, used in §10.1.
[32]
Schwank, J. R., Ferlet-Cavrois, V., Shaneyfelt, M. R., Paillet, P., Dodd, P. E. “Radiation
effects in SOI technologies.” IEEE Transactions on Nuclear Science 50(3), 522–538 (2003). DOI:
10.1109/TNS.2003.812930.
https://ieeexplore.ieee.org/document/1208574 →
Source for dielectric isolation effects: reduced charge-collection volume, elimination of substrate
funneling, and latch-up immunity of devices isolated from the bulk substrate, used in §10.2.
[33]
Komsa, H.-P., Kotakoski, J., Kurasch, S., Lehtinen, O., Kaiser, U., Krasheninnikov, A. V.
“Two-dimensional transition metal dichalcogenides under electron irradiation: defect production and doping.”
Physical Review Letters 109, 035503 (2012). DOI: 10.1103/PhysRevLett.109.035503.
https://doi.org/10.1103/PhysRevLett.109.035503
→ Source for displacement-threshold energies in TMD monolayers and the isolated-point-vacancy character of
irradiation damage in atomically thin sheets, used in §10.2.
[34] Vogl, T., Sripathy, K., Sharma, A., et al. “Radiation tolerance of two-dimensional
material-based devices for space applications.” Nature Communications 10, 1202 (2019). DOI:
10.1038/s41467-019-09219-5.
https://doi.org/10.1038/s41467-019-09219-5 →
Demonstrates negligible performance change in 2D-material devices after γ-ray, proton, and electron
irradiation at space-relevant doses, used in §10.
[35] Zhu, L., et al. “Radiation-tolerant atomic-layer-scale RF system for spaceborne
communication.” Nature 650, 346–352 (2026). DOI: 10.1038/s41586-025-10027-9.
https://www.nature.com/articles/s41586-025-10027-9
→ On-orbit demonstration: a wafer-scale monolayer MoS₂ RF transmit/receive system operated at ~ 517 km LEO
for 9 months with bit error rate < 10⁻⁸, with a predicted ~ 271-year lifetime in GEO flux, used in §10.
13. Equations Appendix
Every numeric result in this paper is derived from the equations below. Source citations refer to §12.
Eq. 1 — Planar memory density
where F² is the cell footprint in lithographic squares (8 for the 2T0C DRAM cell), Fnm is the
half-pitch in nm (28 nm baseline), p is the periphery overhead fraction (0.45 for DRAM), and b is bits per
cell (1 for 2T0C). The 10¹² factor converts nm² to mm².
Worked example — Sophon 2T0C DRAM: D = 10¹² / (8 × 28² × 1.45) × 1 = 110.0 Mb/mm². Source
for cell: [10] (analogous 2D-material 2T0C); validated by
[8][9].
Eq. 2 — Per-die capacity
where Amem-tier is the full footprint of one memory tier (750 mm²) and Nmem-tiers =
32. The 64-tier stack interleaves dedicated logic and memory tiers (32 of each); only the 32 memory tiers
contribute to capacity.
Sophon: C = (110.0 × 750 × 32) / 8000 = 330.2 GB (rounded to 330 GB).
Eq. 3 — 2T0C retention time
The factor of 2 reflects the sense margin: data is reliably recovered while the stored voltage remains above
Vdd/2. Source: [8] (closed-form derivation);
[9] (empirical confirmation).
Worked example: Cnode = 3.0 fF (sum of Cgs,RT ≈ 2.5 fF + Cj,WT
≈ 0.5 fF), Vdd = 0.6 V. The off-current is specified as a
width-normalized density Joff = 10⁻¹⁵ A/µm = 1 fA/µm for the
2D-TMD nFET [2][3]; with a
Read-Transistor channel width WRT = 0.5 µm the absolute leakage is Ioff = Joff
· WRT = 0.5 fA (5 × 10⁻¹⁶ A) at 25 °C: τ = (3.0 × 10⁻¹⁵ × 0.6) / (2 × 5 × 10⁻¹⁶)
= 1.8 s at 25 °C.
This is ≈ 4,800× longer than a 1T1C DRAM cell and reflects the exceptional sub-threshold off-state of the
atomically-thin TMD channel (Ion/Ioff > 10⁸, sub-threshold slope ≈ 75 mV/dec).
Retention derates with junction temperature at ≈ 2× per 10 °C (Arrhenius): τ ≈ 159 ms at 60 °C and ≈ 28 ms
at 85 °C.
Eq. 4 — Refresh power
with Cbits = capacity in bits, frefresh = 1 / Trefresh.
Sophon: at 25 °C the retention τ = 1.8 s (Eq. 3) permits a relaxed refresh interval of
Trefresh = 1.0 s (1.8× margin). P = (330 × 8 × 10⁹ bits) × (1 / 1.0 Hz) × (30 ×
10⁻¹⁵ J/bit) = 0.079 W — effectively negligible. This is the decisive consequence of the 1
fA/µm off-current: refresh power drops by ≈ 3,300× relative to a conventional gain cell.
The on-die controller scales the interval with junction temperature (Eq. 3 derating); even in the worst hot
corner the refresh cost stays small — at 85 °C a 20 ms interval (50 Hz) gives Prefresh ≈
4.0 W, and at a 105 °C excursion a 5 ms interval (200 Hz) gives ≈ 15.8 W.
A nominal 1 W refresh allowance is carried in the power budget (§6) to cover warm
steady-state operation with margin.
Eq. 5 — Per-MAC energy decomposition
Total energy per MAC operation is the sum of memory access and compute.
Sophon uses pure digital CIM (binary sense amplifier + adder tree per column-group.
Sophon BF16 forward MAC: E = (30 fJ/bit × 16 bits) + Eadder-tree,BF16 = 0.480 pJ
+ 0.140 pJ = 0.620 pJ/MAC.
Sophon BF16 backward MAC: add gradient write Ewrite = 20 fJ/bit × 16 bits =
0.320 pJ → 0.940 pJ/MAC total per weight per training step.
Sophon FP8 inference MAC: E = (30 fJ/bit × 8 bits) + Eadder-tree,FP8 = 0.240 pJ
+ 0.070 pJ = 0.310 pJ/MAC.
Eadder-tree,FP8 is computed from per-bit binary adder energy in 28 nm CMOS at 0.6 V
[11] scaled to 2D-TMD: 8 fJ × 8 levels × 0.85 ≈ 0.054 pJ; with sign-bit
and mantissa pipeline overhead the effective figure is 0.070 pJ/MAC. The BF16 adder-tree figure (0.140 pJ)
is twice the FP8 figure because the bit-serial activation broadcast runs for 16 cycles instead of 8. The
fully digital adder tree is the primary energy improvement of the digital-CIM architecture.
Eq. 6 — Active chip power
where Rop is the peak operation rate (FLOPS), u is the utilization fraction, Eper op
is per-FLOP energy (half of per-MAC energy, since 1 MAC = 2 FLOPs).
Sophon FP8 decode (55% util.): P = 4,200 × 10¹² × 0.55 × (0.310 / 2) × 10⁻¹² + 15 W (NoC +
static) = ≈ 373 W (matches §C.3 table: DRAM read 277 W + digital MAC 81 W + NoC 13 W +
static 2 W; the read is the full 0.240 pJ/MAC at the FP8 MAC rate, not halved).
Sophon BF16 forward (55% util.): P = 2,100 × 10¹² × 0.55 × (0.620 / 2) × 10⁻¹² + ~1 W
refresh + 20 W NoC + 2 W static = ≈ 379 W (refresh is negligible at ≈ 0.08 W thanks to the
1 fA/µm off-current).
Sophon backward (55% util.): + gradient write power 2,100 × 10¹² × 0.55 × (0.320 / 2) ×
10⁻¹² = + 185 W extra at FLOP rate, or 370 W at MAC rate. The §C.3 table uses 370 W →
≈ 749 W total.
Utilization 55% is from TPUv4i sustained workload data [12]; peak 100%
used for thermal worst-case.
Eq. 7 — Inference throughput (decode)
From Kaplan et al. [14]:
Sophon 80B FP8 decode: tokens/s = (4,200 × 10¹² × 0.55) / (2 × 80 × 10⁹) =
14,438 tokens/s. Sophon 80B BF16 decode: tokens/s = (2,100 × 10¹² × 0.55)
/ (2 × 80 × 10⁹) = 7,219 tokens/s.
Eq. 8 — Training throughput
From Patterson et al. [13]:
The factor 6 (vs. 2 for inference) accounts for forward (2N) + backward (4N) compute.
Sophon 80B BF16: tokens/s = (2,100 × 10¹² × 0.55) / (6 × 80 × 10⁹) =
2,406 tokens/s/die.
Eq. 9 — Cluster training time
Examples:
- 256-die cluster, 1T tokens: 10¹² / (256 × 2406 × 86400) ≈ 18.8 days.
- 1,024-die cluster, 1T tokens: ≈ 4.7 days.
-
1,024-die cluster, 15T (Llama-3-class [15]): ≈
70.6 days.
Eq. 10 — Energy per token
Sophon FP8 decode: E = 373 W / 14,438 tokens/s = 25.8 mJ/token.
Sophon BF16 decode: E = 379 W / 7,219 tokens/s = 52.5 mJ/token.
Sophon training (time-avg fwd + bwd): E = 564 W / 2,406 tokens/s =
0.234 J/token.
Eq. 11 — Yield (negative binomial with defect clustering)
Source: Cunningham [23]. A = 7.5 cm² die area, D₀ = 0.1 defect/cm²
(mature 28 nm), α = 3 (typical clustering).
Y = (1 + 0.75/3)⁻³ = 0.512 → 51.2% (negative-binomial).
Cross-check with Murphy/Stapper [24]: Y = ((1 − exp(−AD₀)) / AD₀)² =
0.495 → 49.5%. The more conservative Murphy/Stapper value is used as the base wafer yield.
Eq. 12 — M3D stack yield
With Ytier = 0.997 (3 σ M3D process control achievable per imec
[7]): Ystack = 0.997⁶⁴ = 0.825.
Combined yield (base × stack): 0.495 × 0.825 = 0.408 → 40.8% final die yield used in the
BOM calculation (§9).
Eq. 13 — BOM per die
Sophon: BOM = ($51 + 64 × $52) / 0.408 + $60 + $0 + $25 = $8,273 + $85 =
$8,358.
Wafer cost from [25]; tier adder estimated from per-tier mask +
processing economics in [7][5].
Eq. 14 — 3-year TCO
with 26,280 hours = 3 years × 8,760 h/year, PUE = 1.5 [27], ckWh
= $0.10/kWh [26]. Pavg
is the duty-weighted average power.
Sophon inference (30% busy FP8 decode, 70% idle): Pavg = 0.30 × 373 + 0.70 × 3 =
114.0 W → energy 2,996 kWh × $0.15 = $449 → TCO = $8,358 + $449 = $8,807.
NVIDIA Rubin (R200) same duty: Pavg = 0.30 × 1,800 + 0.70 × 250 = 715 W → energy
18,790 kWh × $0.15 = $2,819 → TCO = $82,800 + $2,819 = $85,619.
AMD Instinct MI455X same duty: Pavg = 0.30 × 1,700 + 0.70 × 250 = 685 W → energy
18,002 kWh × $0.15 = $2,700 → TCO = $96,700 + $2,700 = $99,400.
Sophon training (50% busy training, 50% idle): Pavg = 0.50 × 564 + 0.50 × 3 =
283.5 W → energy 7,450 kWh × $0.15 = $1,118 → TCO = $8,358 + $1,118 = $9,476.
Eq. 15 — Effective vertical thermal conductivity (BEOL stack)
Parallel-conduction model with Cu fill fraction φCu = 0.06 (Monolithic Inter-tier Via density ×
via cross-section / total area), kCu = 380 W/m·K, kBEOL = 2.0 W/m·K
[20]:
keff = 0.06 × 380 + 0.94 × 2.0 = 24.7 W/m·K.
Eq. 16 — Steady-state junction temperature
Rstack = (Ntiers × ttier) / (keff × Adie) is the M3D
stack resistance; Rpkg is the package-to-coolant resistance from
[21][22].
Sophon FP8 decode (373 W, liquid Rpkg = 0.05 K/W): Rstack = (64 ×
0.35 × 10⁻⁶) / (24.7 × 7.5 × 10⁻⁴) = 0.00121 K/W (negligible) → Tj = 25 + 373 × 0.0512 =
44.1 °C.
Sophon training avg. (564 W): Tj = 25 + 564 × 0.0512 =
53.9 °C (well below Tjmax = 105 °C).
Eq. 17 — Effective decode throughput with workload-level accelerators
The raw dense FP8 baseline of Eq. 7 can be multiplied by three orthogonal workload-level accelerators on a
single Sophon die. Let s be the speculative-decoding multiplier, q be the quantization multiplier, and Nactive
/ Ntotal be the MoE sparsity ratio. The effective decode throughput becomes:
with assumed multiplier values supported by published technique benchmarks:
-
s = 2.5 for speculative decoding with a 1 B-parameter draft model co-resident on the same
die (k = 4 candidates, 70% mean acceptance per token; the draft consumes ~ 1.4% of the MAC budget)
[29]. -
q = 2.0 for INT4 weight quantization vs. FP8 (halves the bit-serial activation cycle
count without changing the underlying MAC accuracy by more than 1–2 perplexity points on 80B-class
instruction-tuned models) [30]. -
Nactive / Ntotal ∈ [0.05, 0.30] for production MoE configurations
(Mixtral, DeepSeek-V3, frontier-MoE estimates).
Worked example — Sophon 80B dense, INT4 + speculative (FP8 mode): tokens/s = (4,200 × 10¹²
× 0.55 × 2.5 × 2.0) / (2 × 80 × 10⁹) = 72,188 tokens/s/die = ~ 5× raw FP8 baseline.
Worked example — Sophon DeepSeek-V3 MoE (671 B total / 37 B active), FP8 dense weights:
tokens/s = (4,200 × 10¹² × 0.55) / (2 × 37 × 10⁹) = 31,216 tokens/s/die = ~ 18× the
equivalent 671 B dense decode rate.
Note that the three multipliers do not all compose additively in every regime: speculative decoding’s
effective speedup depends on the small-model draft accuracy (which itself depends on the deployment domain),
and the q = 2 INT4 multiplier and the MoE sparsity multiplier compose only when the model architecture
supports both jointly. The benchmark table in §5.A.6 enumerates the realistic combinations.
{💬|⚡|🔥} **What’s your take?**
Share your thoughts in the comments below!
#️⃣ **#PhantaField #PFG1 #Whitepaper**
🕒 **Posted on**: 1782696926
🌟 **Want more?** Click here for more info! 🌟