
✨ Read this insightful post from Hacker News 📖
📂 **Category**:
✅ **What You’ll Learn**:
methodology
This project can be broken down into three parts: gathering data, processing data, and analyzing data.
gathering data
I started by using SEM Rush’s Open.Trends service to find the top websites for each country across all industries. While this can be done manually, i automated the process using the Python libraries BeautifulSoup and Selenium-Python (you can also use the Requests library in this case, but I already had Selenium imported lol). Here’s some pseudo-code to give you an idea of how it was done:
# run a function to get the list of countries Open.Trends has listed on their site
countries = getCountries()
# initialize a dictionary to store the information
d = 💬
# iterate through that list
for country in countries:
# follow semrush's URL formatting and plug in the country using a formatted string
url = f'https://www.semrush.com/trending-websites/💬/all'
# navigate to the URL using Selenium Webdriver
driver.get(url)
# feed the page information into BeautifulSoup
soup = BeautifulSoup(driver.page_source, 'html.parser')
# extract the table data using BeautifulSoup
results = getTableData(soup)
# feed the results into the dictionary
d['country'] = results['country']
d['website'] = results['website']
d['visits'] = results['visits']
# save this into some sort of file
df = pandas.DataFrame(d)
df.save_csv('popular_websites.csv', index=False)NOTE: the quality of this data is subject to the accuracy of SEM rush’s methods. i didn’t really look too deeply into that because their listings were comparable to similar services.
You should now have a dictionary of the most popular websites in each country. A lot of those websites will be porn or malware or both. Let’s try to filter some of those out using the Cyren URL Lookup API. This is a service that uses “machine learning, heuristics, and human analysis” to categorize websites.
Here’s more pseudocode:
# iterate through all the websites we found
for i in range(len(df['website'])):
# select the website
url = df.loc[i,'website']
# call the API on the website
category = getCategory(url)
# save the results
df.loc[i,'category'] = category
# filter out all the undesireable categories
undesireable = [...]
df = df.loc[df['category'] in undesireable]
# save this dataframe to avoid needing to do this all over again
df.save_csv('popular_websites_filtered.csv', index=False)
NOTE: Cyren URL Lookup API has 1,000 free queries per month per user.
COMPLETELY SEPARATE NOTE: You can use services like temp-mail to create temporary email addresses.
Now it’s time to get some screenshots of the websites! If you want to take fullpage screenshots, you will need to use Selenium-Python’s Firefox webdriver. If not, any webdriver is fine. However, you probably don’t want to use full page screenshots as webpage sizes vary a lot and this can make your final results less interpretable.
def acceptCookies(...):
# this function will probably consistent of a bunch of try-exception blocks
# in search of a button that says accept/agree/allow cookies in every language
# ngl i gave up like 1/3 of the way through
def notBot(...):
# some websites will present a captcha before giving you access
# there are ways to beat that captcha
# i didn't even try but you should
# iterate through websites
for i in range(len(df['website'])):
url = df.loc[i,'website]
driver.get(url)
# wait for the page to load
# you shouldn't really use static sleep calls but i did
sleep(5)
notBot(driver)
sleep(2)
acceptCoookies(driver)
sleep(2)
# take screenshots
driver.save_screenshot(f'homepage_⚡_💬.png')
# this call only exists for firefox webdrivers
driver.save_full_page_screenshot(f'homepage_{country.upper()}_{url}.png')NOTE: When doing this, you can use a VPN to navigate to the appropriate country / region to get increase the likelihood of seeing the local web page.
processing data
i mostly followed this tutorial by Grigory Serebryakov on LearnOpenCV. It utilizes an implementation of a ResNet model to extract the features of an image. You can pull the code from his blog post but we do need to load our images in differently. We can use this method by andrewjong (source). We need to save the image file paths for use in our final visualization.
class ImageFolderWithPaths(datasets.ImageFolder):
"""Custom dataset that includes image file paths. Extends
torchvision.datasets.ImageFolder
"""
# override the __getitem__ method. this is the method that dataloader calls
def __getitem__(self, index):
# this is what ImageFolder normally returns
original_tuple = super(ImageFolderWithPaths, self).__getitem__(index)
# the image file path
path = self.imgs[index][0]
# make a new tuple that includes original and the path
tuple_with_path = (original_tuple + (path,))
return tuple_with_pathnow we can load our images using that method.
# identify the path containing all your images
# if you want them to be labeled by country, you will need to sort them into folders
root_path="..."
# transform the data so they are identical shapes
transform = transforms.Compose([transforms.Resize((255, 255)),
transforms.ToTensor()])
dataset = ImageFolderWithPaths(root, transform=transform)
# load the data
dataloader = torch.utils.data.DataLoader(dataset, batch_size=32, shuffle=True)next we initialize and run our model. I needed to adapt Serebryakov’s code slightly to account for how our images were loaded.
# initialize model
model = ResNet101(pretrained=True)
model.eval()
model.to(device)
# initialize variables to store results
features = None
labels = []
image_paths = []
# run the model
for batch in tqdm(dataloader, desc="Running the model inference"):
images = batch[0].to('cpu')
labels += batch[1]
image_paths += batch[2]
output = model.forward(images)
# convert from tensor to numpy array
current_features = output.detach().numpy()
if features is not None:
features = np.concatenate((features, current_features))
else:
features = current_features
# return labels too their string interpretations
labels = [dataset.classes[e] for e in labels]
# save the data
np.save('images.npy', images)
np.save('features.npy', features)
with open('labels.pkl', 'wb') as f:
pickle.dump(labels, f)
with open('image_paths.pkl', 'wb') as f:
pickle.dump(image_paths, f)we should now have 4 sets of data containing our image paths, labels, images, and their extracted features.
analyzing data
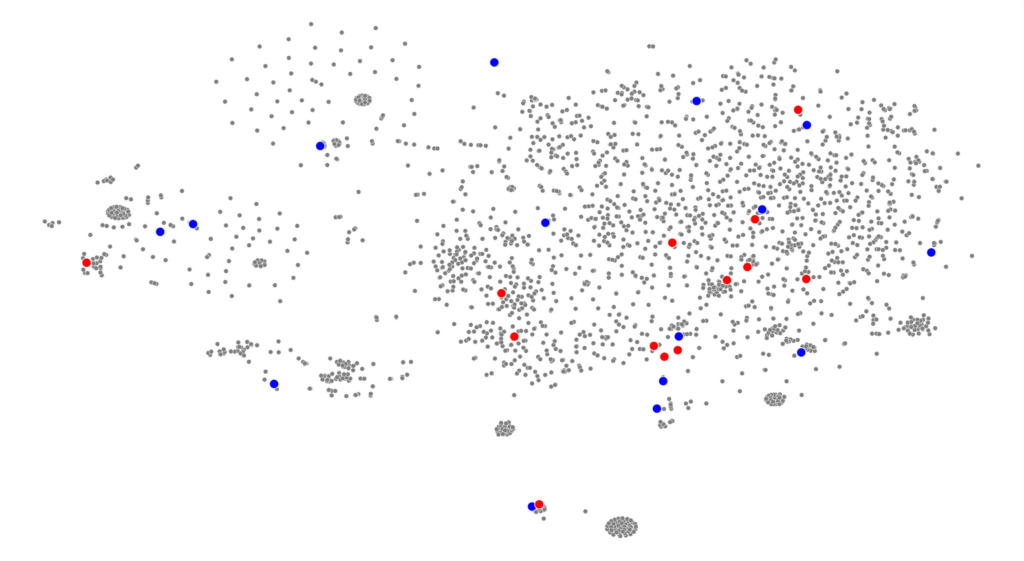
we start by running our data through sci-kit’s tsne implementation. This basically reduces our multidimensional feature arrays down to 2D co-ordinates that we can put on a graph. We can map smaller versions of our screenshots onto those coordinates to see how the machine has organized our websites.
# the s in t-SNE stands for stochastic (random)
# let's set a seed for reproducible results
seed = 10
random.seed(seed)
torch.manual_seed(seed)
np.random.seed(seed)
# run tsne
n_components = 2
tsne = TSNE(n_components)
tsne_result = tsne.fit_transform(features)
# scale and move the coordinates so they fit [0; 1] range
tx = scale_to_01_range(tsne_result[:,0])
ty = scale_to_01_range(tsne_result[:,1)
# plot the images
for image_path, image, x, y in zip(image_paths, images, tx, ty):
# read the image
image = cv2.imread(image_path)
# resize the image
image = cv2.resize(image, (150,100))
# compute the dimensions of the image based on its tsne co-ordinates
tlx, tly, brx, bry = compute_plot_coordinates(image, x, y)
# put the image to its t-SNE coordinates using numpy sub-array indices
tsne_plot[tl_y:br_y, tl_x:br_x, :] = image
cv2.imshow('t-SNE', tsne_plot)
cv2.waitKey()now we can look for any visual patterns in the images. What i found was detailed in the sections above.

i wanted to understand this data through the lens of writing systems, culture (geographically and economically), and technology. So, I found datasets containing that information: writing systems, iso countries with regional codes, and the global north-south divide. They needed to be supplemented with some additional Google searching to make sure we had labels for each country in our dataset.
Here’s a basic walkthrough of how I used this new analysis data.
analysis_data = # import data
# initialize a list to capture a parallel set of labels
# so instead of the country, we can label our data through writing system, etc.
new_labels = []
# iterate through our pre-existing labels and use it to inform our new_labels
for label in labels:
# select the new_label based on the old label (the country name)
new_label = analysis_data['country' == label]
new_labels.append(new_label)
# use the new_labels to colour a scatterplot with our tsne_results
tsne_df = pd.DataFrame({'tsne_1': tx, 'tsne_2': ty, 'label': new_labels})
sns.scatterplot(x='tsne_1', y='tsne_2', data=tsne_df, hue="label")NOTE: The technology argument used a more qualitative methood and is not included here.
we can see the results of those comparisons in the sections above
an answer in progress project
{💬|⚡|🔥} **What’s your take?**
Share your thoughts in the comments below!
#️⃣ **#sabrinas.space**
🕒 **Posted on**: 1771860049
🌟 **Want more?** Click here for more info! 🌟