💥 Explore this insightful post from Hacker News 📖
📂 **Category**:
✅ **What You’ll Learn**:
03 Feb 2026
In these times of interdependency and extreme specialization it does not come
as a surprise that open source projects depend on each other in many ways.
Projects higher in the stack depend on features, provided by projects lower in
the stack – all while driving their development and sorting out issues
specific for this particular project. But it’s hardly breaking news that
isolation between such dependent projects might be hard to overcome, delaying
adoption of new functionality, keeping outdated decisions in place and
generally making the world less enjoyable.
In the ideal world it’s not a problem – folks from different communities are
watching closely what others are doing, understand correctly why are they doing
that and how to apply this knowledge. In reality things are a bit more messy:
we don’t always have bandwidth to follow all interesting and important
projects, and sometimes people from different communities are almost speaking
different languages.
People from HeptapoDB are trying to talk to developers from BernderOS
And that’s exactly where I’m aiming with this blog post. I’ll try to look
through recent Linux kernel changes and identify those that sound interesting
for a database like PostgreSQL. It’s a very superficial overview, and after
more close inspection it might happen I was wrong, but I still hope it can give
some impulse for future patches and discussions.
0. Table of content
So far I was talking about “recent changes interesting for PostgreSQL”. This
needs some unpacking: what is “recent” and “interesting” anyway? For the purpose of this blog post:
-
“Recent” means last few years. For example, I intentionally didn’t include
changes around (understanding of) shared memory ormemfd_create, which I
was experimenting with in the online shared memory resize patch [1] – those
are relatively old, it’s just us, who didn’t get the memo yet. -
“Interesting” means that the change clearly opens new possibilities, improves
performance, or the change is explicitly targeted at databases and people
believe it should be helpful.
Another important aspect of the discussion I’ve left aside on purpose is
portability. PostgreSQL community is known for its efforts to be as portable
between different OS and distributions as possible. This can lead to a
situation when a new shiny feature could not be really adopted, if it’s not
portable enough and handling it as a special case is somehow problematic.
With that’s being said, let’s jump right in.
To explain what uncached buffered IO is, we don’t have to go further than
reading this commit message [2]:
commit 9ad6344568cc31ede9741795b3e3c41c21e3156f
Author: Jens Axboe <[email protected]>
Date: Fri Dec 20 08:47:39 2024 -0700
mm/filemap: change filemap_create_folio() to take a struct kiocb
Patch series "Uncached buffered IO", v8.
The main idea is that normal buffered IO can be unpredictable at times and
consume lots of resources, when reclaiming memory. It’s not always the case,
but at the same time it’s easy to end up in such situation. To address this the patch introduces a new flag called RWF_DONTCACHE:
pwritev2(fd, iov, iovcnt, offset, RWF_DONTCACHE);
When specified, the flag instructs kernel to do following:
-
Reads and writes use page cache, and reads even work like normal buffered
reads, nothing new. -
Writes kick the writeback at the end of the operation, and aren’t synchronous
in this sense. -
Folios outside the IO aren’t touched.
-
Uncached IO takes advantage of the page cache for up-to-date data, but do not
leave anything in the cache.
It’s hard to believe this might be a reasonable thing to do, so I’ve prepared a
small test case. The following graph shows IOPS for two FIO larger than memory
loads on a VM with a very little available memory, which causes heavy reclaim
pressure. The only difference between FIO configuration is whether IO is cached
or uncached.
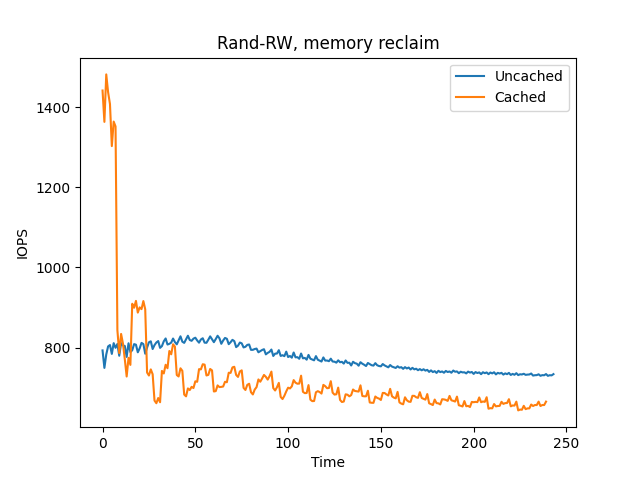
Two FIO random-RW larger than memory workloads on a VM with small amount
of memory.
As you can see, as soon as the cache fills in, performance of the cached load
drops below that of the uncached and stays generally more variable.
About this one I first learn from a colleague. This change seems to be
developed by kernel folks particularly for databases use case, and causes a
whole spectrum of reaction from “meh” to “databases are solved”. It’s actually
not a single commit, but rather a set of changes across different subsystem,
but to have some starting point for now let’s have a look at this [3]:
commit c34fc6f26ab86d03a2d47446f42b6cd492dfdc56
Author: Prasad Singamsetty
Date: Thu Jun 20 12:53:52 2024 +0000
fs: Initial atomic write support
The general idea is simple – many modern NVMe and SCSI devices actually
support atomic writes [4], with a caveat that writes have to satisfy certain
conditions: they have to align on the block size and do not exceed the maximum
atomic write unit size, advertised by the hardware. To close the loop, a new
flag was introduced, which tells kernel to enforce those requirements and do
not split IO operation, if marked as “atomic”:
pwritev2(fd, iov, iovcnt, offset, RWF_ATOMIC);
Originally only single-block writes were supported, with a follow-up to extend
it to multi-block cases, e.g. with a software-based approach for XFS [5] or
bigalloc feature for EXT4 [6].
Atomic writes as a feature was targeting first of all databases, that have to
do some sort of double writing to achieve atomicity when writing out the data.
If we search for “torn pages” in PostgreSQL we’ll find 19 occurrences
warning in one or another way about the hazard of torn writes. Particularly
prominent feature that comes to mind is of course Full Page Image (FPI) [7],
which puts the entire content of a page to WAL preventing partial writes.
Unfortunately there is an elephant in the room – atomic write support requires
direct IO for now, and it’s not clear whether it will be implemented for
buffered IO.
I’ve spent some time trying to come up with ideas how to demonstrate this
feature, or rather how to reproduce a torn write on purpose. Fortunately QEMU
supports emulation of NVMe with atomic operations [8], but somehow I didn’t
manage to make FIO verify mode working. So instead I’ve just forced a bio
split via fiddling with the state of IO in gdb:
# options for QEMU
-device nvme,
id=nvme-ctrl-0,
serial=nvme-1,
atomic.dn=off,
atomic.awun=63,
atomic.awupf=31
-drive file=nvme.qcow2,
if=none,
id=nvm-1
-device nvme-ns,
drive=nvm-1,
bus=nvme-ctrl-0
# Trigger an atomic IO operation, and force bio_split_io_at
$ gdb vmlinux
#0 bio_split_io_at (bio=bio@entry=0xffff88812cfc9f00,
lim=, segs=0xffffc90000c679dc,
max_bytes=, len_align_mask=3)
at block/blk-merge.c:365
>>> set max_bytes = 512
# The call errored out as a fail-safe, when bio were split. In reality no split
would be happening.
$ ./atomic
Write failed: Invalid argument
# The same repeated for a non-atomic IO.
$ ./non-atomic
Success: 8192
$ perf trace -a -e block:block_split
130624.754 non-atomic/10450 block:block_split(dev: 271581184, sector: 272, new_sector: 273, rwbs: "WS", comm: "non-atomic")
Another change is a bit older [9]:
commit cf264e1329fb0307e044f7675849f9f38b44c11a
Author: Nhat Pham
Date: Tue May 2 18:36:07 2023 -0700
cachestat: implement cachestat syscall
The new syscall is essentially a more scalable way to query page cache state
than mincore. From the usage perspective it looks like this:
struct cachestat_range 🔥;
struct cachestat ⚡;
int cachestat(unsigned int fd, struct cachestat_range *cstat_range,
struct cachestat *cstat, unsigned int flags);
One of the claimed use cases was again databases, because it’s obviously
important to know the status of page cache to predict how much IO certain
operation will incur. Interestingly enough there was one PostgreSQL CommitFest
item [10] already regarding this syscall:

Closed CF item about cachestat syscall.
As you can see, in the end it was returned with feedback, mostly because the
proposed usage was to stop prefetching data if the cache is full. It’s not
obvious that this approach would be a performance win, so the discussion
fizzled out. But don’t feel discouraged, that wasn’t the only use case for
cachestat!
In index_pages_fetched function in PostgreSQL we find following commentaries:
We use an approximation proposed by Mackert and Lohman, "Index Scans
Using a Finite LRU Buffer: A Validated I/O Model", ACM Transactions
on Database Systems, Vol. 14, No. 3, September 1989, Pages 401-424.
The Mackert and Lohman approximation is that the number of pages
fetched is
PF =
min(2TNs/(2T+Ns), T) when T <= b
2TNs/(2T+Ns) when T > b and Ns <= 2Tb/(2T-b)
b + (Ns - 2Tb/(2T-b))*(T-b)/T when T > b and Ns > 2Tb/(2T-b)
where
T = # pages in table
N = # tuples in table
s = selectivity = fraction of table to be scanned
b = # buffer pages available (we include kernel space here)
Note the b, which represents amount of buffer pages available. In the
referenced article this variable includes available page cache as well, which
is currently unknown to PostgreSQL. Due to that it’s being calculated based on
effective_cache_size, making the later known as a knob affecting how often an
index scan will be chosen over a sequential scan:
/* b is pro-rated share of effective_cache_size */
b = (double) effective_cache_size * T / total_pages;
But obviously a configuration knob is a suboptimal solution, leaving a gap for
estimating this value more correctly and, what’s more importantly, on the fly
from the information known to PostgreSQL and the state of page cache.
You may have heard about BPF already – it’s being used in many areas,
including networking, monitoring and security. All of those are somewhat
orthogonal to databases, but one new area of application is getting more
popular, namely customization of Linux kernel behaviour via bpf struct ops. One
recent example is custom scheduler class sched_ext [11], which essentially
allows creating a custom Linux scheduler:
SEC(".struct_ops")
struct sched_ext_ops simple_ops = 🔥;
This is already something more interesting for databases: one can imagine a
scheduler, which makes its decisions not only on the state of the system, but
also based on the database specific priorities. For example one can introduce a
priority dispatch queue to favour some types of activity, which the database
considers important at this very moment (serving some critical queries), and
reduce priority for some background jobs. Or the other way around, if we value
stability and robustness, we give background maintenance jobs more priority,
while making everything else wait a tiny bit longer.
sched_ext has eventually found its way into the kernel. But there are more
exciting patches that are currently in development. One of them is cache_ext
[12], a struct ops approach to custom page cache eviction policies.
SEC(".struct_ops")
struct cache_ext_ops fifo_ops = 💬;
Contrary to sched_ext, cache_ext is explicitly targeting databases to
improve typical cases, when a database is mostly serving an OLTP workload, but
the page cache gets washed out due to a couple of large analytical queries.
But wait, there is more! This patch [13] is trying to make io_uring
customizable via BPF, promising better waiting and polling patterns:
static struct bpf_struct_ops bpf_io_uring_ops = {
.verifier_ops = &bpf_io_verifier_ops,
.reg = bpf_io_reg,
.unreg = bpf_io_unreg,
.check_member = bpf_io_check_member,
.init_member = bpf_io_init_member,
.init = bpf_io_init,
.cfi_stubs = &io_bpf_ops_stubs,
.name = "io_uring_ops",
.owner = THIS_MODULE,
};
And the last but not least proposal [14] is about making OOM killer
customizable as well, which might be quite beneficial for memory hungry
databases:
static struct bpf_struct_ops bpf_oom_bpf_ops = {
.verifier_ops = &bpf_oom_verifier_ops,
.reg = bpf_oom_ops_reg,
.unreg = bpf_oom_ops_unreg,
.check_member = bpf_oom_ops_check_member,
.init_member = bpf_oom_ops_init_member,
.init = bpf_oom_ops_init,
.name = "bpf_oom_ops",
.owner = THIS_MODULE,
.cfi_stubs = &__bpf_oom_ops
};
Let’s wait and hope that at least some of those will make it into the kernel.
As we have seen throughout the blog post, there are plenty of exciting things
to try out in PostgreSQL or look forward to and give feedback upon. The
overview was a bit superficial, but I hope it will be enough to stir some
discussions and trigger one or two experiments.
{💬|⚡|🔥} **What’s your take?**
Share your thoughts in the comments below!
#️⃣ **#Whats #Linux #kernel.. #PostgreSQL #Erthalions #blog**
🕒 **Posted on**: 1772539260
🌟 **Want more?** Click here for more info! 🌟