
🔥 Explore this awesome post from Hacker News 📖
📂 **Category**:
💡 **What You’ll Learn**:
Google DeepMind
* Equal contribution
now at: 1xAI 2Epsilon Health 3Seoul National University
4Google
CVPR 2026
Overview
TIPSv2 is the next generation of the TIPS family of
foundational image-text encoders empowering strong performance across numerous multimodal and vision tasks.
Our work starts by revealing a surprising finding, where distillation unlocks superior patch-text alignment over
standard pretraining, leading to distilled student models significantly surpassing their much larger teachers in this
capability. We carefully investigate this phenomenon, leading to an improved pretraining recipe that upgrades our vision-language
encoder significantly. Three key changes are introduced to our pretraining process (illustrated in the figure below):
iBOT++ extends the patch-level
self-supervised loss to all tokens for stronger dense alignment; Head-only EMA reduces training
cost while retaining performance; and Multi-Granularity Captions uses PaliGemma and Gemini
descriptions for richer text supervision. Combining these components, TIPSv2 demonstrates strong performance across 9
tasks and 20 datasets, generally on par with or better than recent vision encoder models, with particularly strong gains
in zero-shot segmentation.
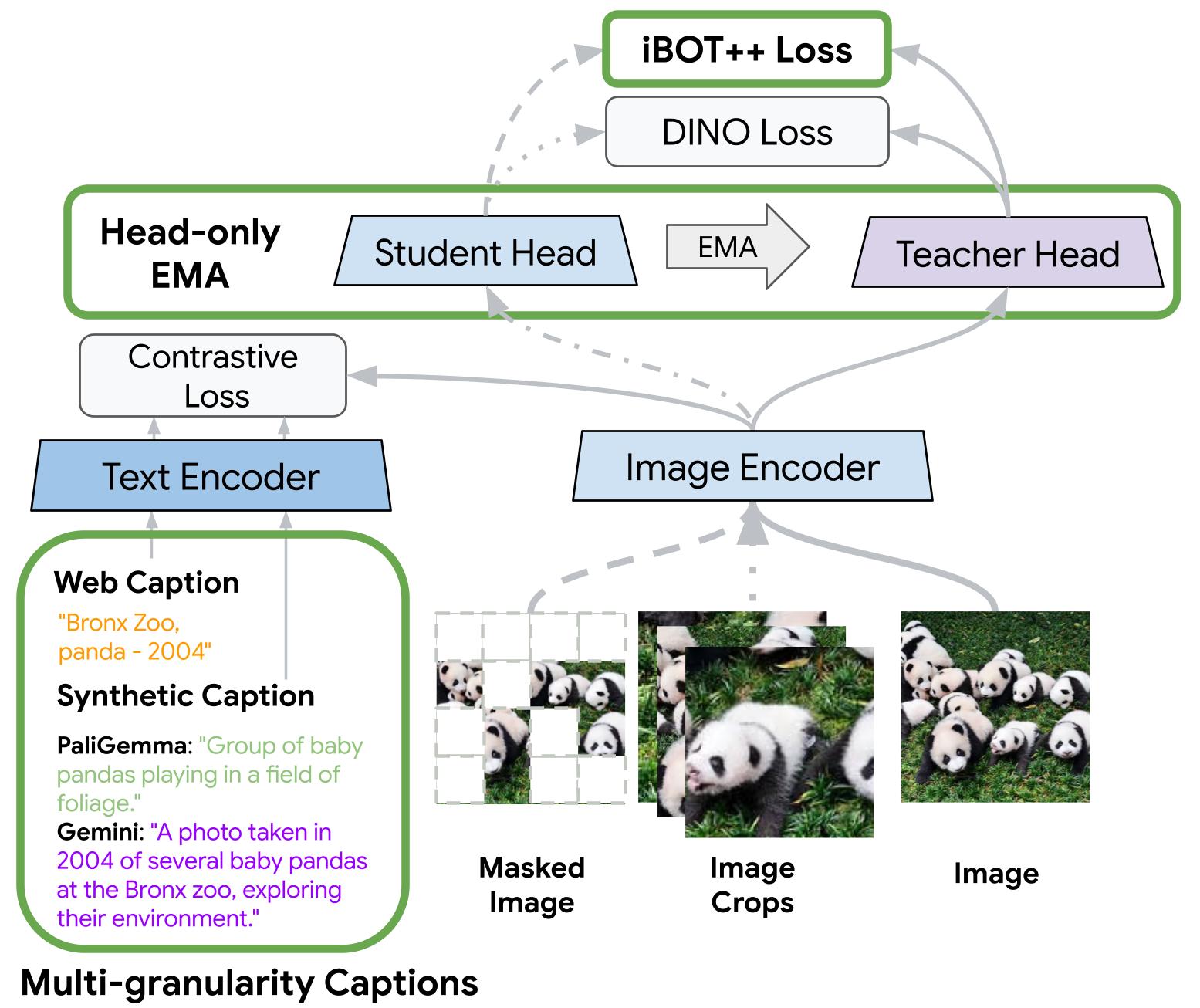
TIPSv2 pretraining overview. TIPSv2 introduces 3 pretraining improvements:
iBOT++ (enhanced MIM loss),
Head-only EMA (memory-efficient self-supervised losses), and Multi-granularity
captions (richer text supervision).
Visualization
PCA Feature Maps
TIPSv2 produces smoother feature maps with well-delineated objects compared to prior vision-language models
(e.g., TIPS and SigLIP2). While DINOv3 also exhibits smooth feature maps, TIPSv2 shows stronger
semantic focus: object boundaries are more precisely delineated and regions show granular semantic details.
We compare ViT-g models of several vision encoders, except for DINOv3, where we compare with the 6× larger ViT-7B.
Select an image below to explore PCA components of patch embeddings.

Image

TIPS

SigLIP2

DINOv2

DINOv3 (7B)

TIPSv2 (ours)
TIPSv2 PCA features
demonstrate more fine-grained semantic separation: backpacks, people, and hiking poles are clearly delineated.
Feature Explorer
Upload your own image and explore TIPSv2 patch embeddings feature maps or applications in zero-shot segmentation or depth and normal prediction. Also available on HuggingFace.
Method
TIPSv2 investigates the differences between pre-training and distillation, motivating the introduction of three
targeted pretraining improvements to standard vision-language models: iBOT++, Head-only
EMA, and Multi-Granularity Text Captions.
Bridging Pre-training and Distillation
We reveal a surprising gap between pre-training and distillation: a smaller ViT-L model distilled from a larger
ViT-g
TIPS teacher dramatically outperforms its teacher in zero-shot segmentation, reversing the trend of all other
evaluation tasks. We observe a similar trend in SigLIP2. In the paper, we ablate the differences between pre-training
and distillation, such as masking
ratio, encoder initialization, frozen or training parameters, and supervision.
Our investigation reveals that the important distinction that causes differences in patch-text alignment between
distillation and pre-training is supervision on visible tokens.
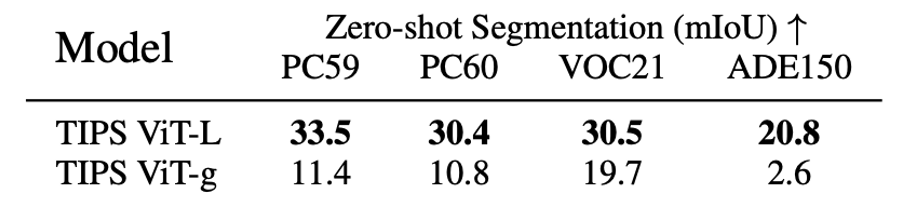
Distillation vs standard pretraining: surprising findings. Zero-shot segmentation for a TIPS
ViT-g pre-trained teacher model and a ViT-L student distilled from the ViT-g teacher. The student model strongly
surpasses the teacher for patch-text alignment.
iBOT++: Enhanced Masked Image Modeling
In our investigation of the gap between distillation and standard pretraining, we find that supervising visible
patches is the key
differentiator. To introduce this improvement in distillation to pretraining, we propose a simple augmentation: iBOT++. Whereas standard
iBOT only supervises masked patch tokens, leaving visible token representations
unconstrained, iBOT++ extends the patch-level self-distillation loss to all patches (both masked and visible),
yielding a +14.1 mIoU gain in zero-shot segmentation on ADE150.
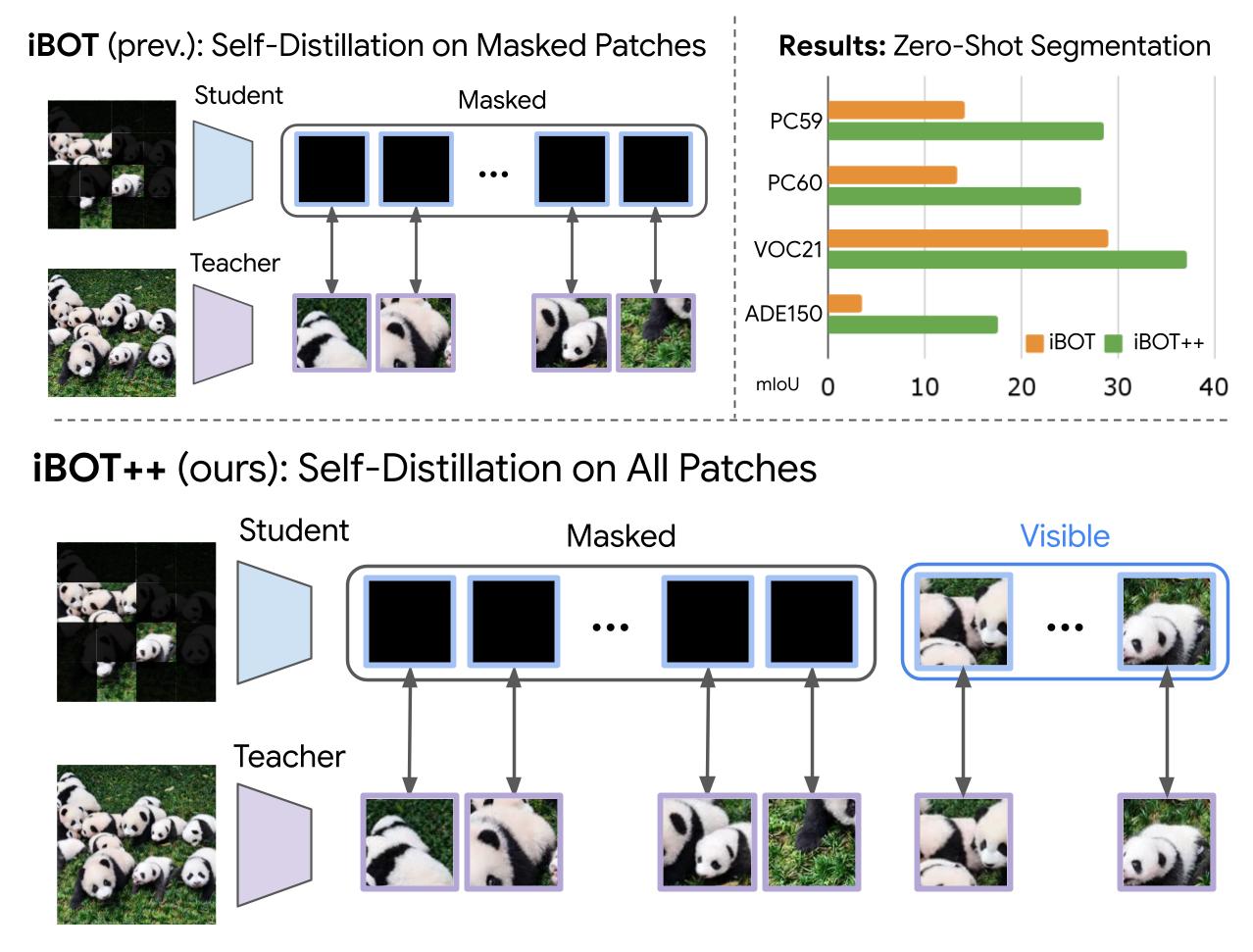
iBOT++. Applies the patch-level loss to all patches (masked and visible),
dramatically
improving patch-text alignment as shown by zero-shot segmentation results.
Head-only EMA
Since the contrastive loss already stabilizes the vision encoder, we apply EMA only to the projector head rather
than the full model. This reduces training parameters by 42% while retaining comparable
performance.
Head-only EMA. Reduces training parameters while maintaining performance.
Multi-Granularity Text Captions
We supplement alt-text and PaliGemma captions with richer Gemini Flash captions, randomly alternating between them
during training to avoid shortcutting on coarse keywords. This boosts both dense and global image-text
performance.
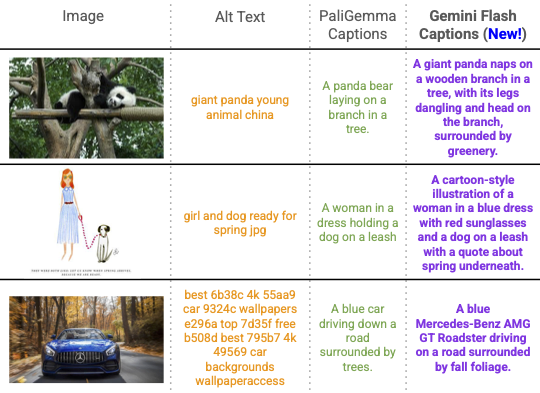
Multi-granularity captions. Image captions at different granularities.
Ablations
We ablate each component cumulatively from the TIPS baseline. iBOT++ alone yields the largest single gain:
a +14.1 mIoU improvement in zero-shot segmentation on ADE150 (3.5 → 17.6),
confirming that extending the patch-level loss to visible tokens is the key driver of dense patch-text alignment.

Ablation studies. Cumulative ablations from the TIPS baseline, each adding one TIPSv2
component on ViT-g.
Results
We evaluate TIPSv2 across a wide range of evaluation categories, including Dense Image-Text
(zero-shot segmentation), Global Image-Text (classification and retrieval), and
Image-Only tasks (segmentation, depth, normals, retrieval, classification). Select a tab below to explore the detailed
results tables.
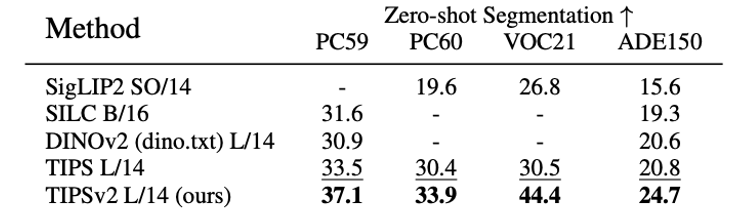
Dense image-text evaluations. TIPSv2 achieves SOTA on all four zero-shot
segmentation benchmarks, outperforming SILC and DINOv2 even though they
use the more complex TCL evaluation protocols.
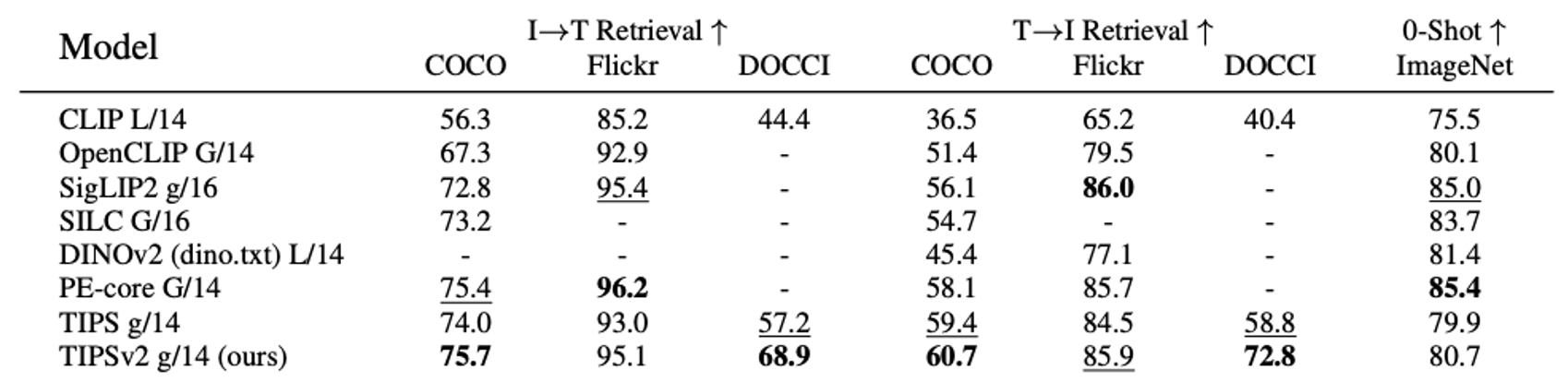
Global image-text evaluations. TIPSv2 achieves best or second-best in 5 of 7 global
evaluations. Notably, TIPSv2-g outperforms PE-core G/14 on 3 of
5 shared evals, despite PE having 56% more parameters and 47× more training pairs.
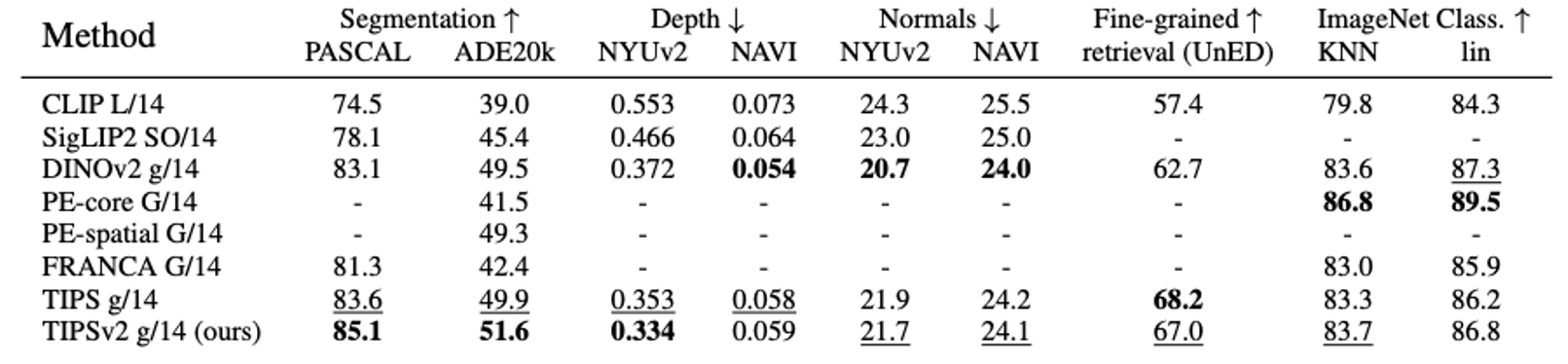
Image-only evaluations. TIPSv2 achieves best or second-best in 7 of 9 image-only evaluations.

DINOv3 vs TIPSv2 comparison. We compare TIPSv2 with DINOv3 at the largest common size between
the two families: ViT-L. Despite DINOv3’s teacher
using 6× more parameters and 15× more images, TIPSv2 wins 4 of 6
shared evaluations including zero-shot segmentation (both using sliding window protocol from TCL in this case).
Acknowledgements
We would like to thank Connor Schenck and Gabriele Berton for thoughtful discussions and suggestions.
We also thank the D4RT project for website template.
graphic design is not my passion
Citation
@inproceedings{cao2026tipsv2,
title = 🔥,
author = 💬,
booktitle = 💬,
year = {2026}
}{💬|⚡|🔥} **What’s your take?**
Share your thoughts in the comments below!
#️⃣ **#Advancing #VisionLanguage #Pretraining #Enhanced #PatchText #Alignment**
🕒 **Posted on**: 1777064295
🌟 **Want more?** Click here for more info! 🌟